как определить сколько нужно тонн на участок дороги, удельный вес бутового камня 1м3, таблица отсева
Благодаря удельному весу щебня появилась возможность вычислить соотношение объема и веса щебня. С помощью этой величины можно рассчитать количество породы в определенном объеме. Осуществляя доставку щебня, в документации указывают его объем и массу.
В случае доставки продукта по автомобильной дороге следует его количество определять в кубометрах, в то время как, осуществляя перевоз товара по воде или железной дороге необходимо использовать такую единицу измерения как килограммы.
Применение
Щебень по своим характеристикам можно разделить на различные фракции, которые используются для определенного вида строительства.
- фракция с размерами 0 5 мм. Она отлично подходит для декора в виде отделки, для преображения вашего ландшафта в саду или дачного участка, отсыпания дорожек. Также используется при создании ЖБ конструкций;
Фракция 0-5 мм
- фракции с размерами
 Широко распространен среди строителей. Материал с такими характеристиками достаточно широко используется в строительстве, в частности, для изготовления бетона и бетонных конструкций, дорог и т.д.;
Широко распространен среди строителей. Материал с такими характеристиками достаточно широко используется в строительстве, в частности, для изготовления бетона и бетонных конструкций, дорог и т.д.;
Фракция 10-20
- фракция 20 40. Материалы данной фракции используются практически во всех строительных сферах: строительство железных дорог, изготовление фундамента, стяжки, благоустройство площадок со строительной техникой;
Фракция 20-40 мм
- фракция с размерами 25 60;
Фракция 25-60 мм
- фракция 40 70 мм
Фракция 40-70 мм
- фракция с размерами 40 200 мм. Более известен как бутовый камень.
 Применяется при сооружении стен и оград.
Применяется при сооружении стен и оград.
Бутовый камень
Каждая фракция обладает различной плотностью. Из этого следует, что щебень, который относится к группе с высокой фракцией, обладает низким показателем насыпной плотности. Эти характеристики должны быть обязательно указаны в сопроводительной документации товара.
Для того чтобы определить плотность щебня (5 20) обращаются в специальные лаборатории. Анализируя материал берут одно ведро субстанции и относят в лабораторию.
Характеристики
Исходя из технических характеристик щебня, его можно подразделить на несколько классов. Главными показателями, на которые обращают внимание, являются: состав поставляемого продукта, его плотность (20 40), фракционный коэффициент, прочность продукта и его способность выдерживать влияние воды и холода.
Различают несколько видов щебня. Основными материалами
Гранитный
- известняковый;
Известняковый
Шлаковый
Гравийный
Материал, который содержит не высокое количество слабых пород, считается более качественным и надежным.
Щебень получают при измельчении природных материалов.
Также можно использовать более дешевый вариант, который получается в результате переработки старого асфальта, кирпича и т.д.
Вторичный
Основным свойством, которое характеризует качество щебня, считается лещадность. Чем больше однородных камней, тем выше плотность. Второстепенными, но не менее важными, свойствами считается хорошая устойчивость к морозам и влиянию воды. Радиоактивность материала также желательно знать.
Радиоактивность в материале наблюдается в определенных количествах (2 класс), то его будут использовать для строительства дорог отдалённых от населения, а щебень первого класса уже можно задействовать в сооружении зданий и жилых домов.
Насыпная плотность
Данный коэффициент используют для того, чтобы определить правильный объем товара. Может получится так, что поставщик загрузил полный кузов щебня, а когда он прибыл на место, то уже не кажется таким полным, как был изначально.
Такое может случиться из – за уплотнения материала во время дороги. Дело в том, что преодолевая большие расстояния грузовой автомобиль все-время трясет, что приводит к уплотнению щебня. Поэтому по прибытию на место товара кажется меньшее количество.
Во избежание конфликтных ситуаций с продавцом пользуются коэффициентом перевода для определения реального веса щебня (5 20). Необходимо учитывать, что у каждого вида щебня имеется свой коэффициент уплотнения. Это позволяет вести учет расходов.
Базовая плотность
Данный коэффициент не стоит воспринимать как какое-то определенное число, так как каждый вид щебня, в зависимости от своих свойств, имеет свою плотность.
Таким образом, гранитный щебень и известняк по объему будут совершенно разные, хоть и при одинаковом весе. Это обусловлено наличием в составе известняка некоторой доли доломитов и кварца.
Осведомленность во фракционной классификации позволит вам осуществить точные расчеты, которые поспособствуют грамотному развитию строительного процесса.

Это доказывает, что определение насыпной плотности (20 40)имеет чрезвычайное значение для приготовления раствора. Такие знания помогут вам сэкономить при строительстве. Ведь чем больше плотность, тем меньше понадобиться использовать цемента.
Прочность
Данное свойство этого продукта имеет большую значимость при выборе материала. Отметим, что плотность щебня выявляется при сжатии горной породы. На основе свойств материала используют специальную маркировку.
Щебень с маркировкой М200-400 имеет слабое значение прочности. Он применяется в основном для создания дизайна.
Создание дизайна
Щебень с маркировкой М500 – 800 относится к группам средней плотности. В эту категорию попадает также популярный щебень м600.
Использование данного материала целесообразно в обустройстве автодорожного покрытия с большими нагрузками.
Строительство автодорог
Также его задействуют для сооружения железобетонных конструкций, которые не нуждаются в особой плотности.
Сооружения из железобетона
Щебень с маркировкой М800 – 1100 имеет высокую прочность и считается самым популярным и часто используемым материалом.
Он хорошо подходит для строительства дорог, а также для изготовления железобетонных конструкций. Щебень с маркировкой М1200 – 1400 отличается повышенной прочностью.
Это обусловлено тем, что он состоит преимущественно из гранитных пород. Однако есть и недостаток данного материала, такой как повышенная радиоактивность. Из-за этого он не используется в строительстве жилых комплексов и помещений, в которых предусмотрено нахождение большого количества людей.
Лещадность
Данное свойство оказывает большое влияние в первую очередь на плотность материала. По своей форме щебень может быть разнообразным. Если преобладает игловидный и пластинчатый камень, то и лещадность выше.
Лещадность
Таким образом, чем больше зерен такой формы тем больше вероятность образования пустот, а меньшее количество соответственно повышает качество материала.
Радиоактивность
Щебень с большой степенью радиоактивности используется только в определенных строениях. К тому же каждый продукт имеет свои сертификаты и заключения, в которых указано данное свойство.
Морозостойкость
Каждый вид щебня имеет свои свойства морозостойкости. Некоторые из них имеют повышенную морозостойкость, а некоторые наоборот. Наиболее оптимальным вариантом, который чаще всего используется в строительстве, является щебень F-300.
Теплопроводность
Не маловажным свойством всех сооружений является способность удерживать тепло.
Гранитный 20 40
Данный вид щебня очень популярен среди строителей и считается одним из самых востребованных. Гранитный щебень с фракционным значением 20 40 отличается высокой прочностью.
На каждое сооружение или строение требуется определенное количество материала.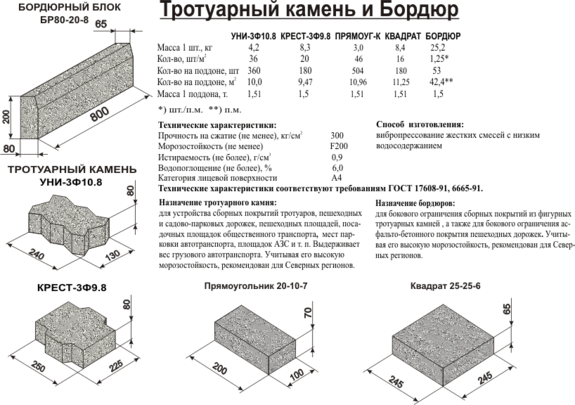 Для того, чтобы не ошибиться с расчетами и закупить то количество щебня которое необходимо, следует знать некоторые величины, такие как: объемный вес, коэффициент уплотнения и др.
Для того, чтобы не ошибиться с расчетами и закупить то количество щебня которое необходимо, следует знать некоторые величины, такие как: объемный вес, коэффициент уплотнения и др.
На этом этапе строительства иногда возникают небольшие проблемы, так как реализация гранитного щебня осуществляется в кубометрах.
От чего же зависит вес гранитного щебня?
Если брать во внимание цельный гранит, то его объемный вес будет 2600 кг/м3. Другое дело, когда гранит поддается дроблению. Естественно его объем уменьшиться и для фракции 20 – 40 будет приблизительно равен 1380 кг, но это не значит, что данная величина будет постоянной.
Гранитный 20 40
На объемный вес влияет множество факторов:
- наличие пыли, особенно в маленьких частицах;
- лещадность;
- соотношение количества зерен с разным размером.
Стоит отметить, что объемный вес может колебаться от 1350 кг до 1400 кг на 1 куб м. Такое колебание зависит от производителя, партии материала, лещадность (уменьшает плотность и увеличивает количество пустот). Щебень, в котором наблюдается большее количество пыли, имеет больший объемный вес.
Такое колебание зависит от производителя, партии материала, лещадность (уменьшает плотность и увеличивает количество пустот). Щебень, в котором наблюдается большее количество пыли, имеет больший объемный вес.
Также удельный вес (5 20) изменяется после транспортировки щебня и его отгрузки. Насыпная плотность оказывает не малое влияние на увеличение веса в кг на кубометр гранитного щебня.
Именно коэффициент уплотнения является тем параметром, который определяет величину уменьшения удельного веса щебня. В случае с гранитным щебнем 20 40 он равен 1,1. Таким образом, объем кубометра данного материала ниже 10% уменьшиться не может после перевозке на транспортном средстве или хранение на складе.
На сегодняшний день речной песок является самым востребованным строительным материалом благодаря своим качествам и не высокой цене. Тут его плотность.
Плиточный клей морозостойкий применяют в тех случаях, когда строительство либо ремонт проводят в осенне-зимний период.
Здесь клей различных производителей.
Отделка стен снаружи играет большую роль и является одним из самых важных этапов работы. Перейдя по ссылке ознакомитесь со стеновыми фасадными панелями.
Также стоит обращать внимание на сопроводительную документацию, которая прилагается к каждой партии продукта. В этих документах должны указываться все необходимые характеристики, в том числе и объемный вес продукта на 1 кубометр.
Более подробно о гранитном щебне 20 40 смотрите на видео:
Количество кубометров в тонне
Перед началом любого строительства необходимо точно рассчитать, сколько материала понадобиться на определенные сооружения. Это очень важный этап, поэтому в строительных компаниях создаются целые отделы для осуществления таких расчётов и составления смет.
Это очень важный этап, поэтому в строительных компаниях создаются целые отделы для осуществления таких расчётов и составления смет.
Но и самостоятельно можно осуществить такие расчёты, если вы сами решили заняться строительством своего дома. Для того, чтобы у вас не осталось лишнего материала или наоборот не хватило его, необходимо грамотно осуществить подсчет веса щебня в 1 м3 или в тонне или осуществить перевод м3 в тонны.
Во избежание перевеса транспорта, который вы нанимаете для транспортировки, нужны грамотные и верные подсчеты для определения количества кубов щебня в 1 тонне.
Для нахождения данного значения обычно пользуются услугами специальных лабораторий. Для определения насыпной плотности щебня проводят специальные тесты с помощью которых и определяют плотность материала. Каким способом возможно перевести тонну щебня в куб?
Для перевода тонны щебня в кубометры следует вес материала разделить на объемную плотность. Рассмотрим на примере. Допустим, вы заказали самосвал, грузоподъемность которого составляет 20 тонн. Итак, вес щебня получается 20000 кг, а его насыпная плотность 1500 кг/м3.
Допустим, вы заказали самосвал, грузоподъемность которого составляет 20 тонн. Итак, вес щебня получается 20000 кг, а его насыпная плотность 1500 кг/м3.
После проведения расчетов мы получаем в результате объем, который равен 13,3 куба. Таким образом, самосвал, грузоподъемность которого составляет 20 тонн, способен перевезти 13,3 куб м продукта.
Напомним, что плотность щебня в 1500 кг/м3 не является постоянной. Она зависит от значения фракций и варьируется в пределах от 1400 до 1600 кг/м3.
Для более удобного расчета можно воспользоваться таблицей, в которой показан вес щебня 1 м3 с учетом значения фракции.
Таблица 1
| Фракция | Марка | Вес |
| 5 10 | М700 – 800 | 1,42 т/м3 или 1420 кг/м3 |
| 5 20 | М700 – 800 | 1,38 т/м3 или 1380 кг/м3 |
| 20 40 | М700 – 800 | 1,36 т/м3 или 1360 кг/м3 |
| 25 60 | М700 – 800 | 1,37 т/м3 или 1370 кг/м3 |
| 40 70 | М700 – 800 | 1,35 т/м3 или 1350 кг/м3 |
| 5 10 | М1200 | 1,44 т/м3 или 1440 кг/м3 |
| 5 20 | М1200 | 1,41 т/м3 или 1410 кг/м3 |
| 20 40 | М1200 | 1,37 т/м3 или 1370 кг/м3 |
| 25 60 | М1200 | 1,38 т/м3 или 1380 кг/м3 |
| 40 70 | М1200 | 1,36 т/м3 или 1360 кг/м3 |
Таблица 2
| Фракция | Марка | Вес |
| 10 20 | М600 | 1,42 т/м3 или 1420 кг/м3 |
| 20 40 | М800 | 1,32 т/м3 или 1320 кг/м3 |
| 40 70 | М600 | 1,27 т/м3 или 1270 кг/м3 |
Выводы
На сегодняшний день щебень является очень популярным и незаменимым материалом в строительстве любого сооружения. Он задействован практически во всех областях строительства.
Он задействован практически во всех областях строительства.
Однако стоит внимательно относиться к его использованию, особенно к определению удельной массы материала. Это сэкономит вам не только время, но и затраченные средства. Читайте материал который расскажет сколько кубов в 1 тонне щебня и про вес куба песка.
Характеристики и разновидности гранитного щебня и отсева
В строительной отрасли активно используется щебень и отсев. Сырье в зависимости от фракций позволяет упрочить цементный раствор, выполнить декоративную облицовку внешней стороны здания и так далее.
Щебень и отсев повсеместно используют в разных строительных отраслях благодаря его характеристикам и свойствам, о которых речь пойдет ниже.
Классификация щебня по маркам
Существует определённая классификация продукта, которая делится на четыре категории:
- Наиболее слабый продукт – М 200.
- Слабый – М 300, 400, 600.
- Прочный – М 800, 1000.

- Сырье высокой прочности – М 1200, 1400.
Классификация прописана в ГОСТ 8267-93. В соответствии с утвержденными стандартами в классификацию входит учет слабых зерен (их количества) от общей массы. Это выглядит следующим образом:
- М 200, 300 присутствие слабых частиц 15%, не более.
- М (морозоустойчивый) 300, 400, 600: доля слабого зерна не должна превышать 10%.
- М 1200, 1400: наиболее низкое содержание породы – не более 5% от общей массы.
О плотности и весе
Изначально определяется плотность рабочего продукта. Средневзвешенные показатели сырья соответствуют 2600 кг/м2. При определении плотности, которая выполняется в лабораторных условиях, следует учитывать среднюю насыпную плотность. То есть какой объемный вес составляет 1 м3 материала в природном состоянии. Чем меньше фракция, тем меньше для приготовления раствора уйдет цемента, и наоборот.
Еще один важный показатель, влияющий на расчёты – это удельный вес гранита.
| Фракция | Характеристика | Лещадность до | Насыпная плотность тонн/м³ | Мощность | Морозостойкость |
| 2-5 | 1 группа | 1,36 | 1200 | F300 | |
| 5-10 | кубовидный | 15% | 1,36 | 1200 | F300 |
| 5-20 | кубовидный | 15% | 1,40 | 1400 | F300 |
| 10-15 | 1 группа | 20% | 1,36 | 1200 | F300 |
| 5-20 | 1 группа | 19% | 1,35 | 1400 | F300 |
| 20-40 | 1 группа | 19% | 1,37 | 1400 | F300 |
| 40-70 | 1 группа | 19% | 1,39 | 1400 | F300 |
| Отсев гранитный | 1,40 | 1200 | F300 |
Понятие удельного веса и его расчётные параметры
Существует такое понятие, как лещадность. Это процентный показатель пластинчатых и игольчатых зерен. Важно понимать, что камень плоской формы в несколько раз увеличивает расход сырья, снижая его показатели.
А вот игольчатые камни и в виде куба, наоборот, повышают показатели. Именно такие камни считаются наиболее перспективными и лучшими. Понятие лещадность вошло в ГОСТ:
- Кубовидный камень содержит до 15% пластинчатых и игольчатых зёрен.
- Улучшенный от 15 до 25%.
- Обычный 25-50%.
О фракции продукта несколько слов
Классификация фракций выглядит следующим образом.
Размер щебня до 5 мм соответствует марке щебня М 1000-1400. В декоративной отделке используется крошка указанных размеров. Щебень с 5 мм фракцией идёт на обустройство террас домов частного сектора и площадок для активного отдыха. Необходимо помнить, что в этом продукте высокий показатель пыли.
Размер до 10 мм соответствует марке М 800-1200. Материал подходит для изготовления бетонных смесей и содержит незначительное количество пыли. Из него можно изготавливать бордюрный камень, тротуарную плитку. Также активно используется в производстве бетона при возведении мостов, укладке дорожного покрытия и фундамента.
Размер до 20 мм соответствует марке М 1400-1600. Материал активно используется для облицовочных работ. Применяется в строительстве мостовых плит и аэродромного покрытия. Считается наиболее востребованным продуктом.
Размер до 40 мм соответствует марке М 1000. Средняя фракция породы 40 мм подходит для производства ж/б изделий. Используется при строительстве и ремонте дорожного полотна. Важно, что содержание пыли минимальное — 0,35%.
Размер до 60 мм соответствует марке М 1000-1200. Порода с размером фракций до 60 мм содержит всего 0,25% пыли. Подходит для обустройства трамвайного полотна и железнодорожных линий. Он характеризуется отсутствием внимания и не представляет практически никакого интереса в строительстве частного сектора.
Размер до 70 мм соответствует марке М 1000-1200. Порода с размером фракций до 70 мм содержит всего 0,68% пыли. Используется при возведении крупных и тяжелых сооружений.
Размер до 300 мм соответствует марке М 1000-1200. В основном камни крупного размера идут для создания ландшафтного продукта: отделка бассейнов, заборов и так далее. В меньшей степени подходит для изготовления бетонных смесей.
О достоинствах и недостатках гранитной породы
Можно с определенной долей уверенности утверждать, что эта порода используется во многих сферах хозяйства. Различные оттенки позволяют применять его в декоративных работах.
К недостаткам можно отнести высокую стоимость, тяжелую добычу и необходимость дополнительной обработки,что влечет за собой определенные накладные расходы. Также в породе могут содержаться вредные примеси.
На заметку: покупать продукт можно и желательно с первым классом радиоактивности.
Отсев щебня: что о нём следует знать?
Отсев — это побочный продукт производства. Зерно с фракцией от 0,1 до 5 мм считается уже отсевом. Впрочем, на него есть определенный спрос. Есть три вида продукта:
- Гранитный.
- Известняковый.
- Гравийный.
Сегодня производится также и вторичная крошка. Это ещё один вид отходов, где задействуют битый щебень, а также изделия из железобетона. Стоимость рассматриваемого материала минимальная.
- Отсев гранитного щебня.Насыпная плотность при фракции 0,1-5 мм составляет 1330 кг/м3. Материал считается стойким к низким температурам, экологичным и безопасным. В нём минимальное количество глиняных примесей и органических веществ.Содержит игольчатых зерен не более 15%. Гранитный отсев, внешне напоминающий песок, успешно используется при укладке верхнего шара дорог, тротуаров, декоративных клумб.
- Гравийный отсев.Размер зерна: 0,16-2,5 мм. Прочность в соответствии М 800, 1000. Органики — не более 0,6%. Насыпная плотность — 1400 кг/м3. Гравийный продукт можно использовать при производстве бетонных смесей, тем самым снизив его себестоимость.Подходит для подсыпки дорожек общего пользования, парковых зон и оформления площадок активного отдыха.
К сведению: стоимость гравийного отсева на 60% дешевле щебня.
- Известняковый отсев.Зерно в пределах 2-5 мм. Вес одного м3 равен 1300 кг. Прочность: М 400, 800. Содержание примесей — до 2%. Известняковый отсев применяется как наполнитель раствора на цементной основе. Он подходит для облицовочных работ внешней стороны зданий.
Заключение
Продукция, о которой мы говорили в этой статье, обладает своими свойствами и характеристиками. В зависимости от своих показателей может применяться в различных направлениях и отраслях строительства.
Похожие услуги
Подводно-технические работыОбладая необходимыми средствами, механизмами и строительной техникой, специалисты компании «Флот Неруд» производят любые подводно-технические работы. Методы, особенности и характер водолазного обследования во многом зависят от поставленных заказчиком целей. Обладая необходимыми средствами, механизмами и строительной техникой, специалисты компании «Флот Неруд» производят любые подводно-технические работы. Методы, особенности и характер водолазного обследования во многом зависят от поставленных заказчиком […]
SDLG: спецтехника высокого качестваКомпания SDLG является одним из крупнейших производителей спецтехники в Китае. По объемам производимой продукции она уступает только таким брендам, как XCMA, Liugong, Longgong. В течение последних пяти лет SDLG входит в пятьдесят лучших изготовителей фронтальных погрузчиков. При этом дата основания этой компании – 1972 год. Компания SDLG является одним из крупнейших производителей спецтехники в Китае. […]
Разработка котлована и вывоз мусораОдним из видов строительных работ, которые часто проводятся, является разработка котлованов. Обустройство котлована – трудоемкий строительный процесс. Во многом от качества проведения работ на данном этапе зависит будущее строительства. Кроме того, необходимо учитывать то, что котлован и вывоз грунта – два неразрывных понятия, поэтому необходимо позаботиться не только о планировке строительной площадке, но и о […]
Щебень : Гранитный отсев
Гранитный отсев (гранотсев) – это материал, полученный в процессе дробления и последующего просеивания гранитной породы. Этот способ является основной технологией производства материала. Также его можно получить как побочный результат при производстве щебня из гранита. Полученная самая мелкая фракция (2-5 мм) называется отсевом. Все, что больше 5 мм – щебень. В этом и есть различие гранитного щебня и гранотсева. Ошибочно считать отсев отходом. Отсев гранитного щебня – стройматериал, который востребован в ремонте, в строительных работах разных областей. Что касается характеристик, то гранотсев не может уступать щебню, так как производится из него путем дробления.
Удельный вес и плотность гранитного отсева
Модуль крупности — 3/10 и 0/5. Насыпная плотность гранитного отсева составляет 1,5 т/м3.
Встречается 2 цвета: красный и серый. Отсев гранитный, фото которого хорошо отображают внешние различия материала, производится по соответствующему ГОСТу, регламентирующему механические и физические свойства стройматериала. Удельный вес отсева гранитного может изменяться, в зависимости от фракций материала.
По физико-механическим свойства не уступает щебню. Характеризуется хорошими антигололедными свойствами, устойчивостью к механическому воздействию, высокой прочностью, устойчивостью к износу, влагонепроницаемостью. За счет таких характеристик, гранотсев повышает прочность изделий, в состав которых он входит. Данный сыпучий материал не способствует таянию снега на тротуарах, так как не содержит химических составляющих. По этой же причине материал не портит обувь и не вредит здоровью.
Применение гранитного отсева
Это широко применяемый строительный материал. При этом не все догадываются, видя гранитный отсев, что это дробленый гранит. Данный сыпучий стройматериал часто встречается на детских площадках, то есть там, где необходимо покрытие, а бетон и щебень могут вызвать повышенный травматизм.
Во многих отраслях используется отсев гранитный, применение его в строительстве разнообразно:
- Изготовление железобетонных изделий, в том числе водопроводных желобов и тротуарной плитки;
- Используется различных фильтрационных системах, очищающих воду от вредных примесей;
- Изготовление асфальтобетонной смеси, строительных, декоративных и различных отделочных материалов;
- Производство декоративных панелей для стен;
- Дорожное строительство;
- Использование зимой как противогололедный сыпучий материал с целью предотвращения скольжения;
- Изготовление керамической продукции.
Гранитный материал уже давно используется в производстве ЖБИ, декоративной и тротуарной плитки, стоков и стеновых материалов. Строительство использует его при устройстве дорожных одежд и асфальта, при заделке швов между плитками.
Особенно востребован материал при благоустройстве территорий. Зимой он просто незаменим и используется для посыпки дорожного покрытия. Антискользящий эффект гранотсева очень высок. Оптимальный размер и удельный вес отсева гранитного, а также его структура, позволяют получить жесткую нескользящую структуру и не выветриваться с дорожек, что очень важно для общественных мест во время гололеда. Однако уменьшение коэффициента скольжения не единственное преимущество материала на дорожках, данный материал не имеет в своем составе химических реагентов, поэтому безопасен для окружающей среды. Кроме того, в некоторых странах мира, где он используется, остатки весной собираются и используются следующей зимой. Такое применение весьма рентабельно и экономически выгодно.
Обладая невысокой стоимостью, данный строительный материал оптимально подходит для обустройства всевозможных площадок и дворовых территорий. При декорировании применяется отсев гранитного щебня мелких фракций. Он идеально подходит для декора клумб, садовых дорожек и прочих элементов ландшафтного дизайна.
Бетон из гранитного отсева
Гранотсев успешно используется в производстве бетона, бетонных и архитектурных изделий. Является основным компонентом, благодаря которому, бетонная смесь может приобрести необходимую плотность и прочность. В отличие от щебня, отсев – дешевый стройматериал, поэтому с его применением можно существенно снизить расходы на строительство. Но главное, что бетон из гранитного отсева не влияет на эксплуатационные характеристики получаемой конструкции или сооружения. В связи с этим, материал успешно применяется во многих областях строительства.
При правильном приготовлении бетона гарантируется высокая прочность конечного продукта. Для этого необходимо правильно использовать отсев. Основное применение гранотсева сводится либо к полной замене песка, либо к использованию в виде дополнительного заменителя. Последний вариант применяется чаще. Правильное приготовление раствора заключается в следующем: из сухого состава необходимо отнять одну часть щебня и одну часть песка. Вместо этого добавить две части измельченного щебня. Дальнейшее использование раствора согласно проекту.
Как используется гранитный отсев для дорожек?
Измельченный щебень – отличный элемент для ландшафтного дизайна приусадебных территорий, для декора, оформления клумб и цветников. Использование этого стройматериала в качестве декоративной крошки позволяет воплотить любые дизайнерские идеи:
- Панорамное проектирование садово-парковых территорий;
- Отсыпка пешеходных и садовых дорожек, площадок;
- Альтернатива цветникам и газонам.
Очень часто данным материалом отсыпаются дорожки. Используя гранитный отсев для дорожек, можно не только получить садовую дорожку любой, даже самой причудливой формы, но и навсегда избавиться от грязи и луж в саду. Обусловлено это водопроницаемостью материала. Кроме того, цвет дорожки также можно выбрать: серый или красный (встречается зеленый). А некоторые мастера чередуют цвета, создавая целые картины в саду. Но для таких дорожек рекомендуется сделать небольшой бордюр. В этом случае даже сильный ливень не размоет покрытие.
Объемный вес(масса) бетона, песка, щебня и т. д.
Объемной массой называют отношение массы данного материала к занимаемому им объему в свободном естественном состоянии, т. е. с учетом разного рода пустот, пор и т. д.
Однако стоит учесть, что объемная масса — величина непостоянная. К примеру, у свежедобытого и слежавшегося песка одного типа она будет сильно отличаться, причиной тому — эффект уплотнения, когда песок слеживается и мельчайшие его частицы прилегают друг к другу плотнее, чем вначале.
Для того чтобы избежать путаницы, во всех справочниках приводят объемную массу материалов в воздушно-сухом состоянии.
Объемный масса строительных материаловТаблица соотношений объема и веса
В таблице приведено примерное соотношение веса и объема при погрузке материалов навалом (насыпная плотность). Так же иногда используют понятие объемный вес материалов. Данные верны только при погрузке/разгрузке без трамбовки или проливки (песка).
| Наименование | в 1 тонне | в 1 м3 |
|---|---|---|
| Песок речной | 0,67 м3 | 1,5 т |
| Песок речной обогащенный | 0,60 м3 | 1,66 т |
| Песок карьерный | 0,71 м3 | 1,4 т |
| Песчано гравийная смесь, ПГС | 0,60 м3 | 1,66 т |
| Глина сырая, вынутая экскаватором | 0,67 м3 | 1,49 т |
| Чернозем сырой, вынутый экскаватором | 0,70 м3 | 1,43 т |
| Снег лежалый | 1,7 м3 | 0,6 т |
| Щебень 5 — 20 | 0,76 м3 | 1,32 т |
| Щебень 20 — 40 | 0,78 м3 | 1,29 т |
| Щебень 20 — 80 | 0,78 м3 | 1,28 т |
| Щебень 40 — 70 | 0,79 м3 | 1,27 т |
| Щебень 80 — 120 | 0,80 м3 | 1,25 т |
| Керамзит М-250 любой фракции | 4 м3 | 0,25 т |
| Керамзит М-300 любой фракции | 3,35 м3 | 0,3 т |
| Керамзит М-350 любой фракции | 2,9 м3 | 0,35 т |
| Керамзит М-400 любой фракции | 2,5 м3 | 0,4 т |
| Асфальтовая крошка | 0,58 м3 | 1,7 т |
Удельный вес песка колеблется от 2,54 до 2,65 в зависимости от того, какие минералы в нем преобладают.
Объемный вес песка зависит от ряда факторов: гранулометрического и минералогического состава, степени уплотнения и влажности. В среднем он равен. 1550 кг/м3, но в отдельных случаях может быть и 1700 кг/м3.
Форма штабелей песка
Песок перевозят навалом, хранят его в конусообразных штабелях или штабелях, имеющих форму усеченного клина.
Объем песка в штабеле-конусе определяют по формуле:
где: D — диаметр основания штабеля; h — высота штабеля; π = 3,14.
Объем песка в штабеле, имеющем форму усеченного клина, подсчитывают по формуле:
где: h — высота штабеля; a и b — длина и ширина штабеля у основания; a1 и b1 — длина и ширина верхней площадки штабеля.
Штабеля обмеряют не раньше, чем через три дня после их отсыпки для того, чтобы дать песку осесть. Полученный объем уменьшают на 10% при влажности песка от 1 до 3% и на 15% при влажности от 3 до 10%. Объем штабелей, насыпанных зимой, уменьшают еще на 15%, учитывая наличие в них снега и льда.
Прочность вяжущих веществ определяют на образцах размером 7,01 X 7,01 X 7,01 см, приготовленных из нормального Вольского песка и вяжущего в соотношении 1:3. Согласно ГОСТ 6139 — 52 нормальным песком считается кварцевый песок крупностью 0,5 — 0,85 мм.
Гранитный щебень 20 40 — характеристики и использование
Гранитный щебень 20 40 — характеристики и использование
Гранитный щебень извлекается в скалистой местности в результате дробления горной породы. Временной промежуток образования гранита насчитывает миллионы лет, объемная масса щебня 20 40 состоит из застывшей магмы с примесью шпата, слюды и кварца. Это самый популярный неорганический материал, используемый в строительстве. Он характеризуется стойкостью к изменению температуры, удобной переработкой в требуемый размер зерен.
Щебень гранитный фракции 20 40 представляет собой куски породы величиной от 20 до 40 мм. Такой размерный ряд идеально подходит при:
- строительстве армирующего фундамента;
- создании железнодорожных насыпей, ремонте трамвайных линий;
- отсыпке автодорог и стоянок;
- возведении временных дорог для прохождения строительной техники к объекту.
Основные характеристики
Объемный вес щебня фракции 20 40 напрямую зависит от качества процесса «грохочения» горной породы. Кубообразные зерна обладают большей плотностью, куски неправильной формы образуют пустоты, где объем воздуха превышает содержание гранита. Зачастую, объемный вес щебня фр 20 40 превышает 50% от реального (если бы измерялся объем чистой породы без воздушных пор).
Показатель веса очень важен при расчете закупочного материала, когда известен объем конструкции под бетонирование. Для этого следует перемножить чистый, а не объемный вес щебня фр 20 40 на кубометры наполняемого объекта и коэффициент уплотнения (обычно – 1,3 для дробленных горных пород).
Плотность гранитной смеси
Средняя плотность щебня 20 40 (масса, деленная на объем) составляет 1,37-1,40 т/м3. Здесь учитывается насыпная величина (с учетом воздушных зазоров). Показатель позволяет рассчитать количество сопутствующей строительной смеси, которая заполнит пустоты между кусками гранита.
Чем выше средняя плотность щебня 20 40, тем меньше цемента, либо песка требуется израсходовать. Следовательно, прочность итоговой конструкции повышается в разы. При планировании перевозки среднефракционного материала, по значению плотности легче подобрать экономичный транспорт.
Лещадность
Показатель раскрывает процент наличия в гравии зерен неправильной формы, когда длина больше ширины в три и более раза. Именно лещадность увеличивает объемный вес щебня фракции 20 40, что негативно сказывается на его плотности и дальнейшей утрамбовке.
Идеальным признается соотношение «неправильной» щебенки в пределах от 15 до 25%. Так как размеры гравия 20-40 мм не позволяют добиться минимального наличия пустот, для данной группы предусмотрен порог от 15 до 35% содержания пластинчатых и игольных зерен.
Если говорить о марке прочности, для объемной массы щебня 20 40 соответствует высокопрочная группа М1200-М1400, что означает минимальное (не более 5%) наличие зерен слабопрочных пород (подвергающихся деформации при водонасыщенном состоянии при пределе прочности 20 Мпа) в природной смеси.
По циклам морозостойкости щебень 20 40 относят к классу F300, когда заморозка и оттаивание массы выдерживает более 300 раз без деформации первоначального состояния.
Перед допуском к реализации гранитный щебень должен проходить ряд лабораторных экспертиз, в результате чего выдается сертификат, что является гарантией долговечной службы возводимого объекта.
каков удельный вес щебня
Вес щебня. Сколько весит куб щебня.
2021-7-13 · Поскольку гранитный щебень является продуктом твердых горных пород удельный его вес, как и удельный вес камней послуживших исходным материалом для производства щебня колеблется в пределах от от 2,2 до 3,3 г/см 3.
Узнай ценуСколько в тонне кубов щебня 20-40: удельный и …
Предприятия реализуют широкий ассортимент сыпучих материалов. Продажи осуществляются в соответствии с количеством и объемом продукции. Поэтому потенциальных потребителей интересует — сколько в тонне кубов щебня 20 …
Узнай ценуУдельный вес щебня 5-20
2021-7-27 · Объемный вес щебня — это величина отношения его веса в сухом состоянии к занимаемому объему. При определении объема следует учитывать пустоты, которые образуются между отдельными частицами щебня.
Узнай ценуУдельный вес щебня
Плотность или удельный вес щебня 5-20 мм — 1,35 т/м 3, для фракции 40-70 мм –1,52т/м 3, для фракции 25-60 мм – 1,37 т/м 3, для отсева 0-5мм – 1,41 т/м 3, фракции 20-40 – 1,35 т/м 3.
Узнай ценуУдельный вес щебня
Удельный вес учитывает наличие пустот между зернами щебня. Средние значения насыпной плотности гранитного гравийного известкового и шлакового щебня указываются в таблицах, а точные в сертификатах качества. …
Узнай ценуНасыпная плотность щебня * ABuildic
2.5 Удельный вес щебня 2.6 Использование декоративного щебня 3 Насыпная плотность щебня 3.1 Факторы влияния на насыпную плотность 3.2 Использование понятия насыпной плотности щебня в практике
Узнай ценуУдельный вес щебня из шлака, удельный вес …
Удельный вес щебня из шлака, удельный вес щебень из шлаков. В таблице 1: указано какой удельный вес 1 одного куба в тн/м3, сколько кг щебня в 1 кубе (кг/м3), сколько вес 1 одного ведра, стандартного емкостью 10 литров и масса 1 …
Узнай ценуУдельный вес щебень, удельный вес щебня.
Удельный вес щебень, удельный вес щебня. В таблице 1: «Удельный вес щебень, удельный вес щебня» указано какой удельный вес 1 одного куба в тн/м3, сколько кг щебня в 1 кубе (кг/м3), сколько вес 1 одного ведра, стандартного …
Узнай ценуТак сколько же щебня в 1 кубе?
2021-8-13 · Щебень имеет прямое отношение к так называемым сыпучим веществам, основной единицей измерения которых служит объем. В зависимости от физических характеристик, происхождения и размера частиц (фракции), щебень будет …
Узнай ценуСколько весит 1 куб щебня: Калькулятор
Сколько весит 1 куб щебня Сыпучие материалы используют для приготовления строительных смесей, бетона, цементных растворов и т.д. Рецептура стройматериалов предполагает строгое соблюдение пропорций, поэтому …
Узнай ценуКакой удельный вес щебня? (2021)
какой удельный вес щебня?. Получи ответ на свой вопрос бесплатно. Напиши нам Всем привет! У меня сейчас стройка в самом разгаре, и для меня настало много вопросов, такие как проект кухни или еще чего нибудь, как сделать …
Узнай ценуСколько мешков отсева в одном кубе?
Сколько тонн в 1 кубе щебня или сколько весит щебень
Ответ на эти и подобные вопросы ищут многие – без щебня не обходится ни одна стройка, ремонт. Его используют в самых различных работах – бетон, изделия из него, строительство дорог, возведение жилья, фундаменты, железобетонные изделия…
Но – чтобы купить щебень правильно, необходимо разобраться в некоторых тонкостях материала. Сколько щебня в машине – вам сразу никто не даст правильный ответ.
В зависимости от рабочих характеристик, размера, насыпной плотности, он имеет различный вес при равном объеме.
Щебень – природный строительный материал, получаемый путем добычи открытым карьерным способом. Большие валуны дробятся, фильтруются по размеру зерна камня, просеивается от посторонних частиц, глины и мусора.
Сколько весит щебень
Основным параметром принято считать удельный вес материала, его насыпную плотность. Чем мельче фракция, тем выше насыпная плотность, чем больше фракция – тем крепче бетонная масса. Плотность зависит от формы камешка – игольчатый, кубовидный или плоский. Наивысшую плотность имеет кубовидная фракция щебня, бетонная масса будет обладать наивысшей прочностью.
Основные показатели, влияющие на удельный вес:
Именно фракция материала оказывает первостепенное влияние на вес щебня. К примеру, зерно 5 – 20 мм имеет плотность 1,36 т.м3, при увеличении зерна 40 – 70 мм, плотность снижается до цифр 1, 32 т.м3.
Данный параметр нельзя упускать при расчетах объема и массы материала.
Также имеет значение происхождение материала – гранитный самый тяжелый, известковый относительно легкий и наименее прочный.
К примеру, из таблицы мы видим, сколько щебня 5 – 20 в кубе – 1,35 тонны.
Что такое объемный вес?
Мы используем объемный вес при определении веса отправляемых отправлений, и мы понимаем, что это не всегда легко понять. Мы хотим разбить детали для вас, чтобы сделать их как можно более ясными. Стоимость транспортировки груза может зависеть от количества места, которое оно занимает на воздушном судне
, а не от фактического веса. Это объемный (или габаритный) вес.Объемный вес отгрузки — это расчет, отражающий плотность упаковки.Менее плотный предмет обычно занимает больше места по сравнению с его фактическим весом.Объемный или габаритный вес рассчитывается и сравнивается с фактическим весом груза, чтобы определить, какой из них больше; больший вес используется для расчета стоимости доставки.
Расчет объемного веса
Объемный вес рассчитывается путем умножения длины на высоту на ширину упаковки и деления результата на объемный коэффициент.Этот коэффициент зависит от единицы измерения.Поскольку мы используем килограммы для расчета стоимости доставки, мы используем следующие формулы для расчета объемного веса:
Имейте в виду, что вес доставки, указанный в подтверждении вашего заказа, может быть основан на наземной доставке или внутренней воздушной доставке от к нашему хабу по адресу
.В зависимости от перевозчика и размера посылки, при оплате наземной доставки Торговца может или не может использоваться расчет объемного веса.Если перевозчик, используемый Продавцом, действительно использует расчет объемного веса для наземных или внутренних воздушных перевозок, при расчете объемного веса будет использоваться другой объемный коэффициент, и объемный вес будет ниже, чем тот, который используется для международных авиаперевозок.Мы надеемся, что это поможет облегчить понимание объемного веса.С любыми дополнительными вопросами обращайтесь в службу поддержки клиентов .
Сколько надо цемента марки 400 на 25 квадратов стяжки с отсева 10см толщиной?
Ответ: Стоит сперва отметить характеристики составляющих, требуемых для приготовления бетона. Плотность цемента марки М400, порядка 1250-1300 килограмм на метр кубический. Плотность гранитного отсева, фракций 0-5 мм или фракции 1-5 мм, примерно 1500-1600 килограмм на метр кубический.
Следующее — это требуемый объем бетонной смеси. Исходя из характеристик вашего покрытия, получим:
25 метров умножим на 0,1 метр = 2,5 кубических метров бетона.
При работе с цементом марки М400 и отсевом, рекомендуются пропорции: 1:3 или 1:4. Если необходим тощий раствор (более низкой плотности и прочности), то можно прибегнуть к пропорциям 1:5. При выборе пропорции, стоит учитывать марку цемента и то, какой продукт на выходе вы хотите получить. Если нужен бетон хорошо работающий на истирание, стойкий к механическим и динамическим воздействиям, высокой влагостойкости, то выберите пропорцию 1:3 (если отсев просеянный и промытый, не содержит пыли, то можно использовать и по порцию 1:4). В этом случае, плотность затвердевшего бетона будет порядка 2400 кг/м3. Это значит, что:
- при пропорции 1:3, понадобится 600 кг цемента и 1800 кг отсева на 1 метр кубический.
- при пропорции 1:4, понадобится 480 кг цемента и 1920 кг отсева на 1 метр кубический.
Учитывая, что для вашей стяжки необходимо около 2,5 кубов бетона, то эти цифры нужно домножить на 2,5 и получим:
- 1500 кг цемента и 4500 кг отсева (1:3).
- 1000 кг цемента и 5000 кг отсева (1:4).
При таких пропорциях получатся качественные и жирные бетонные растворы. Нужен ли такой раствор — решать вам.
Если нет возможности или необходимости изготавливать такие растворы, то смело берите такие пропорции:
Рекомендуем: Как поправить разъехавшуюся паркетную доску?
1:5 или для тощих составов — 1:6.
В этих случаях, на один куб смеси, понадобится:
- при соотношении 1:5 — понадобится 400 кг цемента и 2000 кг отсева.
- пр соотношении 1:6 — понадобится 340 кг цемента и 2040 кг отсева.
При использовании отсева крупных фракций, например 5-10 мм, обязательно включайте в бетонный состав песок. В этом случае, количество цемента в каждой пропорции сохраняете, а вместо, например, 4 частей отсева включаете 2 части песка и 2 части крупнофракционного отсева.
Выбор цемента марки 400 в данном случае оптимален. Далее необходимо определиться с количеством песка, который вы примените в цементном растворе. В итоге по формуле, или с помощью калькулятора расчета, можно определить требуемое количество цемента. Так как у Вас нет перепада пола, то подсчитать можно довольно просто, вычислив по площади и высоте объем, и отняв объем песка. Объём определяем, перемножив площадь на высоту, в данном случае, это двадцать пять квадратов на десять сантиметров (переводи все в миллиметры). Теперь остается добавить лишь долю песка, а это Вы определяете самостоятельно, в зависимости от желаемого типа бетона на выходе.
Для простоты решения, применяйте готовые смеси типа ветонит.
Расход ветонита на 1 м2 при 1 мм слое зависит от вида смеси и колеблется в диапазоне 1,5 — 1,8 кг/ м2.
То есть даже если это с запасом — два килограмма, то получается, что на один квадрат примерно потребуется двадцать килограмм, а на двадцать пять, соответственно около пятисот килограмм, то есть двадцать мешков по двадцать килограмм.
Учтите то, что на упаковке каждого мешка указан расход на один квадратный метр, при толщине в один миллиметр. Исходя из этого и считайте. Что же касается Вашего случая, то примерно отнимите теперь долю песка, и получите результат.
Рекомендуем: Какой должна быть толщина стяжки на водяные теплые полы по нормативам?
Сколько весит куб щебня
Как мы знаем – куб это 1м*1м*1м = ширина*длинна*высота, все это перемножаем – получается 1 куб.
Приведем усредненные данные по фракциям:
Из этих показателей, мы видим, сколько тонн в кубе щебня – здесь роль играет размер зерна. Пример – 20 кубов щебня 5 – 20 – сколько тонн:
20 * 1.37 = 27,400 кг (27 400 кг).
Зная нужные цифры, не стоит покупать точный вес материала, погрешность в 10% гарантирована. Лещадность, фракционность, водопоглощение – эти факторы всегда внесут свои корректировки, поэтому купить щебень необходимо с небольшим запасом.
Лещадность
Данный показатель существенно влияет на качество бетонной массы, на его качество. Чем выше данный показатель. тем хуже будет бетон, его прочность. В его массе будут воздушные прослойки, которые отрицательно сказываются на конечном результате – прочности, надежности, долговечности.
Водопоглощение
Данный показатель имеет важное значение при расчетах веса куба щебня. На этот показатель влияет пористость, размер камня и природа происхождения камня.
Применение
Щебень по своим характеристикам можно разделить на различные фракции, которые используются для определенного вида строительства.
- фракция с размерами 0 5 мм. Она отлично подходит для декора в виде отделки, для преображения вашего ландшафта в саду или дачного участка, отсыпания дорожек. Также используется при создании ЖБ конструкций;
- фракции с размерами 3-8, 10-20 мм. Широко распространен среди строителей. Материал с такими характеристиками достаточно широко используется в строительстве, в частности, для изготовления бетона и бетонных конструкций, дорог и т.д.;
- фракция 20 40. Материалы данной фракции используются практически во всех строительных сферах: строительство железных дорог, изготовление фундамента, стяжки, благоустройство площадок со строительной техникой;
- фракция с размерами 25 60;
- фракция 40 70 мм. Является продуктом с крупными зернами и хорошо подходит для изготовления бетона, который в свою очередь используется для создания массивных сооружений. Если рассчитывать удельный вес, то показатель для щебня фракции 40 70 будет равен примерно 1300-1400 кг/м3;
- фракция с размерами 40 200 мм. Более известен как бутовый камень. Применяется при сооружении стен и оград.
Каждая фракция обладает различной плотностью. Из этого следует, что щебень, который относится к группе с высокой фракцией, обладает низким показателем насыпной плотности. Эти характеристики должны быть обязательно указаны в сопроводительной документации товара.Для того чтобы определить плотность щебня (5 20) обращаются в специальные лаборатории. Анализируя материал берут одно ведро субстанции и относят в лабораторию.
Регуляризация отказовПри увеличении насыпной плотности материала, из-за уменьшения фракции щебня, возможно уменьшение объема загружаемого материала.
в моделях глубокого обучения с помощью Keras
Последнее обновление 27 августа 2020 г.
Простой и мощный метод регуляризации для нейронных сетей и моделей глубокого обучения — это исключение.
В этом посте вы узнаете о методе регуляризации исключения и о том, как применить его к вашим моделям в Python с помощью Keras.
Прочитав этот пост, вы узнаете:
- Как работает метод регуляризации отсева.
- Как использовать выпадение на ваших входных слоях.
- Как использовать выпадение скрытых слоев.
- Как настроить уровень отсева для вашей проблемы.
Начните свой проект с моей новой книги «Глубокое обучение с Python», включая пошаговые руководства и файлы исходного кода Python для всех примеров.
Приступим.
- Обновление, октябрь 2016 г. : Обновлено для Keras 1.1.0, TensorFlow 0.10.0 и scikit-learn v0.18.
- Обновление март / 2017 : Обновлено для Keras 2.0.2, TensorFlow 1.0.1 и Theano 0.9.0.
- Обновление сентябрь / 2019 : Обновлено для Keras 2.2.5 API.
Регуляризация отсева в моделях глубокого обучения с помощью Keras
Фото Trekking Rinjani, некоторые права защищены.
Регуляризация выпадения для нейронных сетей
Dropout — это метод регуляризации для моделей нейронных сетей, предложенный Srivastava, et al. в своей статье 2014 года Dropout: простой способ предотвратить переоснащение нейронных сетей (скачать PDF).
Dropout — это метод, при котором случайно выбранные нейроны игнорируются во время обучения. Они «выпадают» случайно. Это означает, что их вклад в активацию нижестоящих нейронов временно удаляется при прямом проходе, и никакие обновления веса не применяются к нейрону при обратном проходе.
По мере обучения нейронной сети веса нейронов устанавливаются в их контексте в сети. Вес нейронов настраивается на определенные особенности, обеспечивающие некоторую специализацию.Соседние нейроны начинают полагаться на эту специализацию, которая, если зайти слишком далеко, может привести к хрупкой модели, слишком специализированной для обучающих данных. Эта зависимость нейрона от контекста во время обучения называется сложной коадаптацией.
Вы можете себе представить, что если нейроны случайным образом выпадают из сети во время обучения, другие нейроны должны будут вмешаться и обработать представление, необходимое для прогнозирования отсутствующих нейронов. Считается, что это приводит к тому, что сеть изучает несколько независимых внутренних представлений.
В результате сеть становится менее чувствительной к определенному весу нейронов. Это, в свою очередь, приводит к созданию сети, которая способна к лучшему обобщению и с меньшей вероятностью будет соответствовать обучающим данным.
Нужна помощь с глубоким обучением на Python?
Пройдите мой бесплатный двухнедельный курс электронной почты и откройте для себя MLP, CNN и LSTM (с кодом).
Нажмите, чтобы зарегистрироваться сейчас, а также получите бесплатную электронную версию курса в формате PDF.
Начните БЕСПЛАТНЫЙ мини-курс прямо сейчас!
Регуляризация отсева в Керасе
Выпадение легко реализуется путем случайного выбора узлов для выпадения с заданной вероятностью (например,грамм. 20%) каждый цикл обновления веса. Так реализован Dropout в Keras. Отсев используется только во время обучения модели и не используется при оценке навыков модели.
Далее мы рассмотрим несколько различных способов использования Dropout в Keras.
В примерах будет использоваться набор данных сонара. Это проблема бинарной классификации, цель которой состоит в том, чтобы правильно идентифицировать камни и мины по сигналам гидролокатора. Это хороший набор тестовых данных для нейронных сетей, потому что все входные значения являются числовыми и имеют одинаковый масштаб.
Набор данных можно загрузить из репозитория машинного обучения UCI. Вы можете поместить набор данных сонара в текущий рабочий каталог с именем файла sonar.csv.
Мы будем оценивать разработанные модели с помощью scikit-learn с 10-кратной перекрестной проверкой, чтобы лучше выявить различия в результатах.
Имеется 60 входных значений и одно выходное значение, и входные значения стандартизируются перед использованием в сети. Базовая модель нейронной сети имеет два скрытых слоя, первый с 60 единицами, а второй с 30.Стохастический градиентный спуск используется для обучения модели с относительно низкой скоростью обучения и импульсом.
Полная базовая модель приведена ниже.
# Базовая модель в наборе данных сонара из панд импортировать read_csv из keras.models импорт Последовательный из keras.layers import Плотный из keras.wrappers.scikit_learn импорт KerasClassifier от keras.optimizers импортные SGD из sklearn.model_selection импорт cross_val_score из склеарна.предварительная обработка импорта LabelEncoder из sklearn.model_selection import StratifiedKFold из sklearn.preprocessing import StandardScaler из sklearn.pipeline import Pipeline # загрузить набор данных dataframe = read_csv («sonar.csv», header = None) набор данных = dataframe.values # разделить на входные (X) и выходные (Y) переменные X = набор данных [:, 0:60] .astype (float) Y = набор данных [:, 60] # кодировать значения классов как целые числа кодировщик = LabelEncoder () encoder.fit (Y) encoded_Y = кодировщик.преобразовать (Y) # базовый уровень def create_baseline (): # создать модель model = Последовательный () model.add (Dense (60, input_dim = 60, Activation = ‘relu’)) model.add (Плотный (30, активация = ‘relu’)) model.add (Плотный (1, активация = ‘сигмоид’)) # Скомпилировать модель sgd = SGD (lr = 0,01, импульс = 0,8) model.compile (loss = ‘binary_crossentropy’, optimizer = sgd, metrics = [‘precision’]) модель возврата оценщики = [] Estimators.append ((‘стандартизировать’, StandardScaler ())) оценщики.append ((‘mlp’, KerasClassifier (build_fn = create_baseline, epochs = 300, batch_size = 16, verbose = 0))) pipeline = Трубопровод (оценки) kfold = StratifiedKFold (n_splits = 10, shuffle = True) результаты = cross_val_score (конвейер, X, encoded_Y, cv = kfold) print («Базовая линия:% .2f %% (% .2f %%)»% (results.mean () * 100, results.std () * 100))
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 18 19 20 21 22 23 24 25 26 27 28 29 30 000 000 34 35 36 37 38 39 40 41 | # Базовая модель в наборе данных сонара из pandas import read_csv from keras.модели импортируют Sequential из keras.layers import Dense from keras.wrappers.scikit_learn import KerasClassifier from keras.optimizers import SGD from sklearn.model_selection import cross_val_score proningfrom sklearn model_selection import StratifiedKFold из sklearn.preprocessing import StandardScaler из sklearn.pipeline import Pipeline # загрузить набор данных dataframe = read_csv («sonar.csv «, header = None) dataset = dataframe.values # разделить на входные (X) и выходные (Y) переменные X = набор данных [:, 0:60] .astype (float) Y = dataset [:, 60] # кодировать значения класса как целые числа encoder = LabelEncoder () encoder.fit (Y) encoded_Y = encoder.transform (Y) # baseline def create ): # создать модель model = Sequential () model.add (Dense (60, input_dim = 60, activate = ‘relu’)) model.add (Dense (30, activate = ‘relu’)) model.add (Dense (1, activate = ‘sigmoid’) ) # Скомпилировать модель sgd = SGD (lr = 0,01, импульс = 0,8) model.compile (loss = ‘binary_crossentropy’, optimizer = sgd, metrics = [‘precision’]) return model оценок = [] оценок.append ((‘standardize’, StandardScaler ())) оценок.append ((‘mlp’, KerasClassifier (build_fn = create_baseline, epochs = 300, batch_size = 16, verbose = 0 ))) pipeline = Pipeline (оценка) kfold = StratifiedKFold (n_splits = 10, shuffle = True) results = cross_val_score (pipeline, X, encoded_Y, cv = kfold) print («Базовый показатель:%.2f %% (% .2f %%) «% (results.mean () * 100, results.std () * 100)) |
Примечание : Ваши результаты могут отличаться из-за стохастической природы алгоритма или процедуры оценки или различий в числовой точности. Попробуйте запустить пример несколько раз и сравните средний результат.
При выполнении примера оценочная точность классификации составляет 86%.
Использование исключения на видимом слое
Dropout можно применить к входным нейронам, называемым видимым слоем.
В примере ниже мы добавляем новый слой Dropout между входом (или видимым слоем) и первым скрытым слоем. Коэффициент отсева установлен на 20%, что означает, что каждый пятый вход будет случайным образом исключен из каждого цикла обновления.
Кроме того, как рекомендовано в исходной статье о Dropout, на весовые коэффициенты для каждого скрытого слоя накладывается ограничение, гарантирующее, что максимальная норма весов не превышает значения 3. Это делается путем установки аргумента kernel_constraint в поле Плотный класс при построении слоев.
Скорость обучения была увеличена на порядок, а импульс — до 0,9. Это повышение скорости обучения также рекомендовалось в исходной статье для отсева.
Продолжая приведенный выше базовый пример, приведенный ниже код проверяет ту же сеть с отключением ввода.
# Пример исключения из набора данных сонара: видимый слой из панд импортировать read_csv из keras.models импорт Последовательный из keras.layers import Плотный из кераса.слои импортировать Dropout из keras.wrappers.scikit_learn импорт KerasClassifier из keras.constraints import maxnorm от keras.optimizers импортные SGD из sklearn.model_selection импорт cross_val_score из sklearn.preprocessing import LabelEncoder из sklearn.model_selection import StratifiedKFold из sklearn.preprocessing import StandardScaler из sklearn.pipeline import Pipeline # загрузить набор данных dataframe = read_csv («sonar.csv», header = None) набор данных = фрейм данных.ценности # разделить на входные (X) и выходные (Y) переменные X = набор данных [:, 0:60] .astype (float) Y = набор данных [:, 60] # кодировать значения классов как целые числа кодировщик = LabelEncoder () encoder.fit (Y) encoded_Y = encoder.transform (Y) # выпадение во входном слое с ограничением веса def create_model (): # создать модель model = Последовательный () model.add (Dropout (0.2, input_shape = (60,))) model.add (Dense (60, активация = ‘relu’, kernel_constraint = maxnorm (3))) модель.добавить (Плотный (30, активация = ‘relu’, kernel_constraint = maxnorm (3))) model.add (Плотный (1, активация = ‘сигмоид’)) # Скомпилировать модель sgd = SGD (lr = 0,1, импульс = 0,9) model.compile (loss = ‘binary_crossentropy’, optimizer = sgd, metrics = [‘precision’]) модель возврата оценщики = [] Estimators.append ((‘стандартизировать’, StandardScaler ())) Estimators.append ((‘mlp’, KerasClassifier (build_fn = create_model, epochs = 300, batch_size = 16, verbose = 0))) pipeline = Трубопровод (оценки) kfold = StratifiedKFold (n_splits = 10, shuffle = True) результаты = cross_val_score (конвейер, X, encoded_Y, cv = kfold) print («Видно:%.2f %% (% .2f %%) «% (results.mean () * 100, results.std () * 100))
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 14 18 19 20 21 22 23 24 25 26 27 28 29 30 000 000 34 35 36 37 38 39 40 41 42 43 44 | # Пример исключения из набора данных сонара: видимый слой из pandas import read_csv from keras.модели import Sequential from keras.layers import Dense from keras.layers import Dropout from keras.wrappers.scikit_learn import KerasClassifier from keras.constraints import maxnorm from keras.optimizer 9000 SGD import SGD. model_selection import cross_val_scoreиз sklearn.preprocessing import LabelEncoder из sklearn.model_selection import StratifiedKFold из sklearn.preprocessing import StandardScaler из sklearn.конвейерный импорт Pipeline # загрузить набор данных dataframe = read_csv («sonar.csv», header = None) dataset = dataframe.values # разделить на входные (X) и выходные (Y) переменные X = dataset [:, 0:60] .astype (float) Y = dataset [:, 60] # кодировать значения классов как целые числа encoder = LabelEncoder () encoder.fit (Y) encoded_Y = encoder.transform (Y) # выпадение во входном слое с ограничением веса def create_model (): # create model model = Sequential () model.add (Dropout (0.2, input_shape = (60,))) model.add (Dense (60, activate = ‘relu’, kernel_constraint = maxnorm (3))) model.add (Dense (30, activate = ‘relu’, kernel_constraint = maxnorm (3))) model.add (Dense (1, activate = ‘sigmoid’)) # Скомпилировать модель sgd = SGD (lr = 0,1, импульс = 0,9) model.compile (loss = ‘binary_crossentropy’, optimizer = sgd, metrics = [‘precision’]) модель возврата оценок = [] оценок.append ((‘standardize’, StandardScaler ())) Estimators.append ((‘mlp’, KerasClassifier (build_fn = create_model, epochs = 300, batch_size = 16, verbose = 0))) pipeline = Pipeline (оценки ) kfold = StratifiedKFold (n_splits = 10, shuffle = True) results = cross_val_score (pipeline, X, encoded_Y, cv = kfold) print («Видно:% .2f %% (% .2f %%) «% (results.mean () * 100, results.std () * 100)) |
Примечание : Ваши результаты могут отличаться из-за стохастической природы алгоритма или процедуры оценки или различий в числовой точности.Попробуйте запустить пример несколько раз и сравните средний результат.
Выполнение примера дает небольшое снижение точности классификации, по крайней мере, при однократном тестировании.
Использование исключения на скрытых слоях
Dropout можно применить к скрытым нейронам в теле вашей сетевой модели.
В приведенном ниже примере Dropout применяется между двумя скрытыми слоями и между последним скрытым слоем и выходным слоем. Снова используется коэффициент отсева в 20%, поскольку это ограничение по весу для этих слоев.
# Пример исключения из набора данных сонара: скрытый слой из панд импортировать read_csv из keras.models импорт Последовательный из keras.layers import Плотный из keras.layers import Dropout из keras.wrappers.scikit_learn импорт KerasClassifier из keras.constraints import maxnorm от keras.optimizers импортные SGD из sklearn.model_selection импорт cross_val_score из sklearn.preprocessing import LabelEncoder из склеарна.model_selection import StratifiedKFold из sklearn.preprocessing import StandardScaler из sklearn.pipeline import Pipeline # загрузить набор данных dataframe = read_csv («sonar.csv», header = None) набор данных = dataframe.values # разделить на входные (X) и выходные (Y) переменные X = набор данных [:, 0:60] .astype (float) Y = набор данных [:, 60] # кодировать значения классов как целые числа кодировщик = LabelEncoder () encoder.fit (Y) encoded_Y = encoder.transform (Y) # выпадение скрытых слоев с ограничением веса def create_model (): # создать модель model = Последовательный () модель.add (Dense (60, input_dim = 60, Activation = ‘relu’, kernel_constraint = maxnorm (3))) model.add (Выпадение (0.2)) model.add (Dense (30, активация = ‘relu’, kernel_constraint = maxnorm (3))) model.add (Выпадение (0.2)) model.add (Плотный (1, активация = ‘сигмоид’)) # Скомпилировать модель sgd = SGD (lr = 0,1, импульс = 0,9) model.compile (loss = ‘binary_crossentropy’, optimizer = sgd, metrics = [‘precision’]) модель возврата оценщики = [] Estimators.append ((‘стандартизировать’, StandardScaler ())) оценщики.append ((‘mlp’, KerasClassifier (build_fn = create_model, epochs = 300, batch_size = 16, verbose = 0))) pipeline = Трубопровод (оценки) kfold = StratifiedKFold (n_splits = 10, shuffle = True) результаты = cross_val_score (конвейер, X, encoded_Y, cv = kfold) print («Скрытый:% .2f %% (% .2f %%)»% (results.mean () * 100, results.std () * 100))
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 18 19 20 21 22 23 24 25 26 27 28 29 30 000 000 34 35 36 37 38 39 40 41 42 43 44 45 | # Пример исключения из набора данных сонара: скрытый слой из pandas import read_csv from keras.модели import Sequential from keras.layers import Dense from keras.layers import Dropout from keras.wrappers.scikit_learn import KerasClassifier from keras.constraints import maxnorm from keras.optimizer 9000 SGD import SGD. model_selection import cross_val_scoreиз sklearn.preprocessing import LabelEncoder из sklearn.model_selection import StratifiedKFold из sklearn.preprocessing import StandardScaler из sklearn.конвейерный импорт Pipeline # загрузить набор данных dataframe = read_csv («sonar.csv», header = None) dataset = dataframe.values # разделить на входные (X) и выходные (Y) переменные X = dataset [:, 0:60] .astype (float) Y = dataset [:, 60] # кодировать значения классов как целые числа encoder = LabelEncoder () encoder.fit (Y) encoded_Y = encoder.transform (Y) # выпадение скрытых слоев с ограничением веса def create_model (): # create model model = Sequential () model.add (Dense (60, input_dim = 60, activate = ‘relu’, kernel_constraint = maxnorm (3))) model.add (Dropout (0.2)) model.add (Dense (30, activate = ‘relu’ , kernel_constraint = maxnorm (3))) model.add (Dropout (0.2)) model.add (Dense (1, activate = ‘sigmoid’)) # Скомпилировать модель sgd = SGD (lr = 0,1, импульс = 0,9) model.compile (loss = ‘binary_crossentropy’, optimizer = sgd, metrics = [‘precision’]) модель возврата оценок = [] оценок.append ((‘standardize’, StandardScaler ())) Estimators.append ((‘mlp’, KerasClassifier (build_fn = create_model, epochs = 300, batch_size = 16, verbose = 0))) pipeline = Pipeline (оценки ) kfold = StratifiedKFold (n_splits = 10, shuffle = True) results = cross_val_score (pipeline, X, encoded_Y, cv = kfold) print («Скрытый:% .2f %% (% .2f %%) «% (results.mean () * 100, results.std () * 100)) |
Примечание : Ваши результаты могут отличаться из-за стохастической природы алгоритма или процедуры оценки или различий в числовой точности.Попробуйте запустить пример несколько раз и сравните средний результат.
Мы видим, что для этой проблемы и для выбранной конфигурации сети использование исключения в скрытых слоях не привело к повышению производительности. Фактически производительность была хуже базовой.
Возможно, потребуются дополнительные эпохи обучения или потребуется дальнейшая настройка скорости обучения.
Советы по использованию Dropout
Исходная статья о Dropout предоставляет экспериментальные результаты по набору стандартных задач машинного обучения.В результате они предоставляют ряд полезных эвристик, которые следует учитывать при использовании исключения на практике.
- Как правило, используйте небольшое значение выпадения нейронов, составляющее 20% -50%, из которых 20% служат хорошей отправной точкой. Слишком низкая вероятность имеет минимальный эффект, а слишком высокое значение приводит к недостаточному обучению сети.
- Используйте большую сеть. Вы, вероятно, получите лучшую производительность, когда dropout используется в более крупной сети, что дает модели больше возможностей для изучения независимых представлений.
- Использовать выпадение как для входящих (видимых), так и для скрытых объектов. Применение отсева на каждом уровне сети показало хорошие результаты.
- Используйте большую скорость обучения с затуханием и большим импульсом. Увеличьте скорость обучения в 10–100 раз и используйте высокое значение импульса 0,9 или 0,99.
- Ограничение размера веса сети. Большая скорость обучения может привести к очень большому весу сети. Было показано, что наложение ограничений на размер сетевых весов, таких как регуляризация максимальной нормы с размером 4 или 5, улучшает результаты.
Дополнительные ресурсы по выбыванию
Ниже приведены некоторые ресурсы, которые можно использовать, чтобы узнать больше о отсеве в нейронных сетях и моделях глубокого обучения.
Сводка
В этом посте вы открыли для себя метод регуляризации отсева для моделей глубокого обучения. Вы узнали:
- Что такое дропаут и как оно работает.
- Как можно использовать отсев в собственных моделях глубокого обучения.
- Советы по получению наилучших результатов от исключения на ваших собственных моделях.
У вас есть вопросы по поводу отсева или по поводу этой должности? Задайте свои вопросы в комментариях, и я постараюсь ответить.
Разрабатывайте проекты глубокого обучения с помощью Python!
Что, если бы вы могли разработать сеть за считанные минуты
… всего несколькими строками Python
Узнайте, как это сделать в моей новой электронной книге:
Deep Learning With Python
Он охватывает сквозной проект по таким темам, как:
Многослойные персептроны , сверточные сети и Рекуррентные нейронные сети и другие…
Наконец-то привнесите глубокое обучение в
Ваши собственные проекты
Пропустить академики. Только результаты.
Посмотрите, что внутриАлгоритм обучения с отсевом — ScienceDirect
https://doi.org/10.1016/j.artint.2014.02.004 Получение прав и содержимогоАннотация
Отключение — это недавно представленный алгоритм для обучения нейронных сетей путем случайного отбрасывания единиц во время обучения для предотвращения их совместная адаптация. Математический анализ некоторых статических и динамических свойств отсева предоставляется с использованием стробирующих переменных Бернулли, достаточно общих, чтобы учесть отсевы в модулях или соединениях, и с переменной скоростью.Эта структура позволяет провести полный анализ ансамблевых усредняющих свойств отсева в линейных сетях, что полезно для понимания нелинейного случая. Усредняющие по ансамблю свойства отсева в нелинейных логистических сетях являются результатом трех фундаментальных уравнений: (1) аппроксимация математических ожиданий логистических функций с помощью нормализованных геометрических средств, для которых выводятся границы и оценки; (2) алгебраическое равенство между нормализованными геометрическими средними логистических функций и логистикой средств, которое математически характеризует логистические функции; и (3) линейность средних относительно сумм, а также произведений независимых переменных.Результаты также распространяются на другие классы передаточных функций, включая выпрямленные линейные функции. Ошибки аппроксимации имеют тенденцию отменять друг друга и не накапливаются. Выпадение также может быть связано со стохастическими нейронами и использоваться для прогнозирования частоты срабатывания и обратного распространения, рассматривая обратное распространение как усреднение по ансамблю в линейной сети с выпадением. Более того, свойства сходимости отсева можно понять с точки зрения стохастического градиентного спуска. Наконец, для свойств регуляризации выпадения, ожидание градиента отсева — это градиент соответствующего ансамбля аппроксимаций, регуляризованный с помощью адаптивного члена спада веса со склонностью к самосогласованной минимизации дисперсии и разреженным представлениям.
Ключевые слова
Машинное обучение
Нейронные сети
Ансамбль
Регуляризация
Стохастические нейроны
Стохастический градиентный спуск
Обратное распространение
Среднее геометрическое
Минимизация
000 статейМинимизация
000 статейАвторские права © 2014 Авторы. Опубликовано Elsevier B.V.
Рекомендуемые статьи
Цитирующие статьи
DEEPCON: прогнозирование контакта с белками с использованием расширенных сверточных нейронных сетей с выпадением | Биоинформатика
377″> 1 Введение
Для белка, аминокислотная последовательность которого получена с использованием устройства для секвенирования белка, трехмерные (3D) модели могут быть предсказаны с использованием моделирования шаблона или ab initio . Методы шаблонного моделирования выполняют поиск других подобных белковых последовательностей в базе данных последовательностей, трехмерные структуры которых уже были экспериментально определены с помощью экспериментов в мокрой лаборатории, и используют их для прогнозирования трехмерных моделей входной последовательности.Общее количество белковых структур, определенных с помощью экспериментальных методов, таких как рентгеновская кристаллография и спектроскопия ядерного магнитного резонанса, в настоящее время ограничено 147 817 по состоянию на январь 2019 г. (Berman, 2000). Последовательности белков, для которых невозможно найти такие шаблоны, должны быть предсказаны ab initio , то есть без использования каких-либо структурных шаблонов. Для предсказания структуры белковых последовательностей, структурные матрицы которых не обнаружены, предсказанные белковые контакты служат драйвером для сворачивания (Michel et al., 2018; Wang et al. , 2017).
Контакты остаток-остаток или контакты между остатками (или просто контакты) определяют, какие пары аминокислот должны быть близки друг к другу в трехмерной структуре, то есть пары, которые находятся в контакте, должны оставаться близкими, а те, которые не находятся, должны оставаться дальше . Как определено в экспериментах по критической оценке предсказания структуры белка (CASP) (Монастырский и др. , 2016; Moult и др. , 2018), пара остатков в белке считается находящейся в контакте, если их углерод бета-атомы (углерод альфа для глицина) ближе, чем 8 Å в нативной (экспериментальной) структуре.В истинной (или предсказанной) матрице контактов не все контакты одинаково важны. Локальные контакты, с разделением последовательностей менее шести остатков и контакты ближнего действия (с разделением последовательностей от 6 до 12 остатков) не очень полезны для построения точной 3D-модели. Они необходимы для реконструкции локальных вторичных структур, но бесполезны для построения свернутых белков. Однако контакты средней дальности, контактные пары с разделением последовательностей между 12 и 23 остатками и дальнодействующие контакты, разделенные по крайней мере 24 остатками в последовательности белка, необходимы для построения точных моделей.
Все ведущие группы, участвующие в последнем эксперименте по критической оценке предсказания структуры белка (CASP) 13, включая метод AlphaFold DeepMind, используют контакты (или интервалы расстояний) для предсказания структуры белка ab initio . Эти контакты могут быть предсказаны с относительно высокой точностью для последовательностей белков, которые имеют от сотен до тысяч совпадений в базах данных последовательностей белков, таких как UNICLUST30 (Mirdita et al. , 2017) и Uniref100 (Suzek et al., 2007). Полученные совпадения последовательностей в форме множественного выравнивания последовательностей (MSA) служат входными данными для алгоритмов и методов машинного обучения для прогнозирования карт контактов. В то время как общая цель прогнозирования структуры белка заключается в прогнозировании трехмерных моделей (трехмерная информация) на основе последовательностей белков (одномерная информация), предсказанные контакты белков служат промежуточным этапом (двухмерная информация). В отсутствие машинного обучения контакты предсказываются на основе выравнивания последовательностей белков на основе принципа, согласно которому эволюционное давление накладывает ограничения на эволюцию последовательностей из поколения в поколение (Marks et al., 2011). Предсказанные контакты с помощью этих методов, основанных на коэволюции, являются ключевыми входными данными для методов на основе машинного обучения, которые обычно предсказывают более точные контакты.
Хотя Eickholt и Cheng (2012) были первой группой, применившей глубокое обучение для прогнозирования контактов, в настоящее время наиболее успешные методы прогнозирования контактов используют сверточные нейронные сети (CNN), в которые подается комбинация функций, созданных из нескольких выравниваний последовательностей и других последовательностей. -производные функции.После того, как группа Дзинбо Сюй впервые применила CNN для прогнозирования контактов (Wang et al. , 2017), было обнаружено, что CNN особенно хорошо подходят и очень эффективны для решения задачи прогнозирования контактов, в основном из-за их способности изучать перекрестные каналы ( перекрестная информация) (например, взаимосвязь между прогнозируемой доступностью растворителя и прогнозируемой вторичной структурой). В Adhikari et al. (2018), мы демонстрируем, что одна сеть на основе CNN обеспечивает значительно лучшую производительность по сравнению с усиленной сетью глубоких убеждений.Точно так же в Jones and Kandathil (2018) авторы демонстрируют, что базовый метод на основе CNN может легко превзойти другой современный мета-метод, основанный на базовых нейронных сетях. Хотя недавний прогресс в прогнозировании контактов изначально был связан в основном с коэволюционными особенностями, созданными с использованием таких методов, как CCMpred (Seemayer et al. , 2014) и FreeContact (Kaján et al. , 2014), недавние результаты (AlQuraishi, 2019; Jones and Kandathil, 2018; Mirabello and Wallner, 2018) предполагают, что сквозное обучение возможно в ближайшем будущем, когда алгоритм глубокого обучения может полностью способствовать повышению производительности, а эти функции, созданные вручную, могут оказаться избыточными.Большинство недавних успешных методов прогнозирования контактов, как показали недавние результаты CASP, доступны для публичного использования. Например, такие методы, как RaptorX (Wang et al. , 2017), MetaPSICOV (Jones et al. , 2015), DNCON2 (Adhikari et al. , 2018), PconsC3 (Michel et al. ). , 2017) и PconsC4 (Michel et al. , 2018) доступны либо в виде загружаемого инструмента, либо в виде веб-сервера. Каждый из этих методов использует очень разные архитектуры CNN, разные наборы входных функций и самокурирующиеся наборы данных для обучения и тестирования своих методов.
С точки зрения формата входных и выходных данных проблема предсказания контакта с белками аналогична предсказанию глубины по монокулярным изображениям (Eigen, 2014) в компьютерном зрении, то есть предсказанию глубины 3D по 2D-изображениям. В задаче прогнозирования глубины входом является изображение размером H × W × C, где H — высота, W — ширина и C — количество входных каналов, а выход — двумерная матрица размера H × W, значения которой представляют интенсивность глубины. Точно так же в задаче прогнозирования контакта с белками выходом является карта вероятности контакта (матрица) размером L × L, а на входе — характеристики белка размером L × L × N, где L — длина последовательности белка, а N — количество входных каналов.Прогнозирование глубины обычно включает три канала (красный, зеленый и синий или оттенок, насыщенность и значение), в то время как в последнем у нас гораздо большее количество функций, таких как 56 или 441 (Jones and Kandathil, 2018). Из-за большого количества входных каналов общий объем входных данных становится большим, что ограничивает глубину и ширину архитектур глубокого обучения для обучения и тестирования. Это также сильно влияет на время обучения и требует для обучения высокопроизводительных графических процессоров. Эти проблемы, вызванные большим количеством входных каналов, также наблюдаются в других задачах, таких как предсказание генотипа растений по гиперспектральным изображениям.Матрица контакта с белками и ее входные элементы симметричны по диагонали. Большинство современных методов (включая эту работу) рассматривают как верхний, так и нижний треугольники (выше и ниже диагональной линии) для обучения, но для прогнозирования и оценки усредняйте оценки достоверности в верхнем и нижнем треугольнике.
Задача предсказания структуры белка имеет некоторые дополнительные уникальные характеристики. Во-первых, не все входные характеристики белков двумерны. Входные характеристики, такие как длина белковой последовательности, являются скалярными или 0-мерными (0D).Для таких входных функций мы создаем канал с одинаковым значением во всем канале. Точно так же входные функции, такие как предсказания вторичной структуры, являются одномерными (1D), и мы создаем два канала для каждой входной 1D-функции длиной L: первый канал путем копирования вектора L раз для создания матрицы L × L, а второй канал — путем транспонирование входного вектора признаков и последующее копирование L раз для создания матрицы L × L. Другой способ сгенерировать двумерную матрицу из одномерного вектора — вычислить внешнее произведение вектора с его собственным транспонированием.Другие входные объекты, которые являются 2D, копируются во входной объем как есть. Кроме того, длина белковой последовательности может варьироваться от нескольких остатков до нескольких тысяч остатков, что подразумевает переменный объем входных признаков. Размер каждой двумерной функции (преобразованной в каналы) будет зависеть от длины белка. В отличие от реальных изображений, эти входные функции нелегко изучить / понять визуально для понимания того, что изучают сети. Набор данных для обучения и тестирования, который мы можем использовать, также ограничен.В отличие от других общедоступных наборов данных, размер набора данных о структуре белка не может быть значительно увеличен, потому что ежегодно экспериментально определяется только до 11 тысяч новых структур. Что еще больше уменьшает этот набор данных, так это сходство между многими депонированными структурами. На этих белках, если мы выполним некоторые базовые сокращения избыточности, такие как сохранение только белков с более чем 20% сходством последовательностей и белков со структурами высокого разрешения, количество белков, доступных для обучения, сократится всего до примерно пяти тысяч (Wang and Dunbrack, 2003 г.).Несмотря на то, что данные кажутся ограниченными по сравнению со многими другими наборами данных, некоторые утверждают, что этого достаточно, чтобы охватить принципы сворачивания белков. Кроме того, типичная карта контактов с белками, которая представляет собой бинарную матрицу, содержит около 95% нулей и 5% единиц (Jones et al. , 2015).
Трехмерные модели реальных объектов и белковых структур имеют принципиальное отличие. 3D-модели белков не масштабируются. Объект, например стул, в реальном мире может быть крошечным или большим.Белки также могут быть большими или маленькими, но размер структурных узоров всегда физически фиксирован. Например, размер альфа-спирали (общий строительный блок многих белковых структур) одинаков для белков любого размера. Расстояние между атомами углерода-альфа — это фиксированное физическое расстояние, независимо от того, находятся ли спирали в небольшом спиралевидном белке, таком как белок C-MYB мыши, или в большом спиральном белке, таком как гемоглобин. Из-за этой уникальной характеристики белковых структур еще предстоит полностью понять, насколько полезны глубокие архитектуры, такие как U-Nets (Ronneberger et al., 2015) могут быть использованы для прогнозирования контактов с белками, хотя некоторые группы разработали методы прогнозирования контактов с использованием таких архитектур (Michel et al. , 2018). Подобно проблеме предсказания глубины, конечной целью в этой области является разработка методов, которые можно масштабировать для предсказания карты физических расстояний (в ангстремах). Поскольку необработанное прогнозирование расстояния слишком сложно, некоторые группы разработали методы, которые могут прогнозировать контакты при различных порогах разделения последовательностей (Xu, 2018) и демонстрируют, что такое объединение диапазонов расстояний улучшает прогнозирование контактов при одном стандартном пороговом расстоянии, таком как стандарт 8 Å.
В этой работе мы демонстрируем, что расширенные остаточные сети с выпадающими слоями лучше всего подходят для решения проблемы предсказания контакта с белками. Можно утверждать, что результаты небольшого набора данных могут не соответствовать большим наборам данных. Кроме того, результаты, полученные с использованием одного вида функций, могут не соответствовать другим типам входных функций. Например, методы, которые хорошо работают для объектов на основе последовательностей (таких как вторичные структуры), могут не работать для объектов, созданных непосредственно из выравнивания нескольких последовательностей (таких как ковариационная матрица и матрица точности).При обучении на наборе данных DeepCov, состоящем из 3456 белков, с использованием того же набора данных и входных функций для обучения, наш метод достигает на 6-15% более высокой точности на наборе данных белков PSICOV150 (независимый набор тестов), когда верхние L / 5 и L / Оцениваются 2 дальнодействующих контакта, соответственно (L — длина белка). Точно так же при обучении на наборе данных DNCON2, состоящем из 1426 белков, с использованием того же набора данных для обучения и тестирования, одна сеть в нашем методе достигает на 4,8% более высокой точности на большом расстоянии (верхняя L).Хотя DNCON2 использует двухуровневый подход в сочетании с объединением 20 моделей, мы используем единую сеть. Хотя мы сокращаем входную длину белка до 256 для всех белков в наших обучающих экспериментах, после обучения наши модели могут делать прогнозы для белка любой длины. Важно отметить, что, хотя наша общая архитектура нова, мы не первая группа, которая применяет расширенные остаточные сети для предсказания контакта с белками. На встрече CASP13 группа DeepMind была первой группой, которая представила, что расширенные сверточные слои подходят для решения этой проблемы.
387″> 2.1 Наборы данных
Для обучения наших моделей в наших экспериментах мы используем два набора данных: (i) набор данных DNCON2 (Adhikari et al. , 2018), доступный по адресу http://sysbio.rnet.missouri.edu/dncon2/ и (ii) Набор данных DeepCov (Jones and Kandathil, 2018) доступен по адресу https://github.com/psipred/DeepCov. Следуя практике глубокого обучения, для каждого эксперимента мы рассматриваем три подмножества — обучающее подмножество, подмножество проверки и независимый набор тестов.Набор данных DNCON2 состоит из 1426 белков длиной от 30 до 300 остатков. Набор данных был курирован до эксперимента CASP10 в 2012 году, и структуры белков в наборе данных имеют разрешение от 0 до 2 Å. Эти белки фильтруются по 30% идентичности последовательностей для удаления избыточности. Из полного набора данных мы используем 1230 белков для обучения, а оставшиеся 196 — в качестве набора для проверки. Мы обнаружили, что белок с PDB ID 2PNE в проверочном наборе был пропущен во время оценки в методе DNCON2, и поэтому мы тоже его пропускаем.Мы обучаем и проверяем наш метод с использованием 1426 белков и тестируем 62 белковых мишени в эксперименте CASP12. Белок-мишень CASP12 имеет длину от 75 до 670 остатков. Для оценки нашего метода на наборе данных CASP12 мы прогнозируем контакты для всей белковой мишени и оцениваем контакты на полной мишени (или доменах). Набор данных DeepCov состоит из 3456 белков, используемых для обучения и проверки моделей, то есть настройки гиперпараметров. Модели, обученные с использованием набора данных DeepCov, тестируются на независимом наборе данных PSICOV, состоящем из 150 белков.
391″> 2.3 Характеристики ввода
В наших экспериментах мы используем два типа функций — ковариационные признаки (как в методе DeepCov) и признаки последовательности, созданные с использованием различных методов прогнозирования (как в методе DNCON2).Функции последовательности состоят из восьми групп функций в качестве входных данных для обучения и проверки наших моделей. К ним относятся скалярные значения, такие как длина последовательности, одномерные характеристики, такие как доступность растворителя и прогнозы вторичной структуры, а также двумерные функции, такие как функции, вычисленные на основе матрицы оценок для конкретной позиции, информация о разделении последовательностей, предварительно вычисленные статистические потенциалы, функции, вычисленные из вводить множественное выравнивание последовательностей и прогнозы совместной эволюции на основе выравнивания.В общей сложности мы используем 29 уникальных функций в качестве входных данных, которые мы внедряем в 56 входных каналов. Для каждой 0D (скалярной) функции мы копируем значение во весь канал. Точно так же мы копируем каждую двумерную входную функцию как есть в окончательный входной том как один канал. Для каждой входной одномерной характеристики для белка длиной L мы создаем два канала: первый канал, копируя вектор L раз, чтобы создать матрицу L × L, и второй канал, транспонировав вектор входных характеристик, а затем копируя L раз, чтобы создать Матрица L × L.Хотя максимальная длина белка в этом наборе данных составляет 300, мы обрезаем все входные характеристики до длины 256, чтобы самый длинный белок имел входной объем 256 × 256 × 56. Для обучения все белки с длиной меньше 256 равны 0- дополнены так, чтобы все входные объемы имели одинаковый размер 256 × 256 × 56. Функция ковариации состоит из 441-канальной ковариационной матрицы, рассчитанной с использованием общедоступного скрипта (cov21stat) и набора данных в пакете DeepCov. Для этого набора данных входной объем для каждого белка составляет L × L × 441.Для генерации множественных сопоставлений последовательностей для набора данных CASP и набора данных DNCON2 мы следуем подходу использования HHsearch (Söding, 2005) с базой данных UniProt20 (выпуск 2016/02), за которым следует JackHmmer (Finn et al. , 2011) с база данных UniRef90 (выпуск 2016 г.), как описано в методе DNCON2 (подробности см. в нашей статье DNCON2). Эти базы данных общедоступны по адресу http://sysbio.rnet.missouri.edu/bdm_download/dncon2-tool/databases/. Выравнивания белков в наборе данных DeepCov и наборе данных PSICOV150 были скопированы из соответствующего репозитория DeepCov.
398″> 2.5 Сетевые архитектуры
Мы начинаем наши обучающие эксперименты со стандартными сверточными нейронными сетями (или полностью сверточными сетями), каждой из которых предшествует слой пакетной нормализации и активация ReLU. Мы обнаружили, что производительность таких сетей падает после 32–64 сверточных слоев. Затем мы проектируем остаточный блок, состоящий из двух сверточных слоев, каждому из которых предшествует слой пакетной нормализации и активация ReLU.Устанавливая общее количество сверточных фильтров в каждом слое равным 64, мы проектируем четыре остаточные сети: (i) обычная остаточная сеть с глубиной (количеством блоков) в качестве ключевого параметра, (ii) архитектура со вторым слоем пакетной нормализации в каждый остаточный блок заменяется выпадающим слоем, (iii) мы заменяем последний сверточный слой расширенным сверточным слоем со скоростью расширения, чередующейся между 1, 2 и 4, и (iv) архитектурой, которая представляет собой комбинацию второй и третьей архитектуры, я.е. мы заменяем второй слой пакетной нормализации на выпадающий слой, а второй сверточный слой заменяем расширенным сверточным слоем с чередующимися скоростями расширения 1, 2 и 4 (см. рис. 2). Мы также протестировали множество других вариантов архитектуры, таких как размеры фильтров 16, 24 и 32, а также различные способы переключения между уровнями пакетной нормализации и слоями исключения. В среднем эти архитектуры были ненамного лучше, чем четыре архитектуры, которые мы обсуждали выше.
Рис.2.
Остаточная сетевая архитектура, предназначенная для обучения и оценки. ( a ) Стандартный остаточный блок, ( b ) Стандартный остаточный блок со вторым слоем пакетной нормализации, замененным выпадающим слоем, ( c ) Стандартный остаточный блок со вторым сверточным слоем, замененным расширенными свертками, и ( d ) ) Стандартный остаточный блок с выпадением и растяжением
Рис. 2.
Остаточная сетевая архитектура, предназначенная для обучения и оценки.( a ) Стандартный остаточный блок, ( b ) Стандартный остаточный блок со вторым слоем пакетной нормализации, замененным выпадающим слоем, ( c ) Стандартный остаточный блок со вторым сверточным слоем, замененным расширенными свертками, и ( d ) ) Стандартный остаточный блок с выпадением и расширением
Используя набор данных DNCON2 в качестве набора для обучения и проверки и целевые объекты CASP12 в качестве тестового набора данных, мы сравнили точность полностью сверточной сети (FCN) и четырех остаточных архитектур — стандартной остаточной сети, остаточная сеть с расширением, остаточная сеть с выпадением и остаточная сеть с расширением и выпадением.В полностью сверточных сетях и остаточных сетях мы экспериментировали с добавлением слоев исключения разными способами и обнаружили, что чередование слоев пакетной нормализации и слоев исключения дает наилучшую производительность (Zagoruyko and Komodakis, 2016). В нашей стандартной остаточной сети с 64 слоями, имеющими 64 фильтра 3 × 3 в каждом слое, мы протестировали значения выпадения 0,2, 0,3, 0,4 и 0,5. Когда мы оценивали эти модели с использованием точности максимальной дальности L / 5 (P L / 5-LR ) и всей средней и большой точности (P NC-MLR ), мы обнаружили, что конкретное значение отсева не имеет значения, пока у нас есть отсеивающие слои.Для большинства наших экспериментов мы фиксировали 0,3 в качестве параметра для наших слоев отсева (т.е. оставляем 70% веса).
Поскольку наши выводы перекликаются с выводами Загоруйко и Комодакис (2016), мы также выдвигаем гипотезу о том, что проблема «уменьшающегося повторного использования признаков» ярко выражена в проблеме прогнозирования контактов и что слои отсева частично решают эту проблему. Фактически, мы наблюдали до 6% прироста в P L / 5-LR , когда мы случайным образом заменяли некоторые из начальных слоев пакетной нормализации в полностью сверточных слоях всего с 16 слоями (каждый из которых имеет 64 фильтра).Эти результаты показывают, что отсевные слои при правильном использовании могут быть очень эффективными в сетевых архитектурах для прогнозирования контактов с белками. При оценке на независимом наборе данных CASP12, состоящем из 62 целей, мы обнаруживаем, что остаточные сети с расширением и выпадением работают лучше всех четырех других архитектур по всем показателям точности: P L / 5-LR , P L / 2-LR , P L-LR и P NC-MLR (см. Рис. 3). Мы называем эту остаточную сеть с растяжением и выпадением методом DEEPCON.
Рис. 3.
Сравнение точности набора данных CASP12, полученного от различных архитектур при обучении и проверке моделей с использованием набора данных DNCON2
Рис. 3.
Сравнение точности набора данных CASP12, полученного от различных архитектур при моделировании обучено и подтверждено с использованием набора данных DNCON2
405″> 3.1 Сравнение сетевых архитектур с другими сетевыми архитектурами
Чтобы протестировать нашу архитектуру DEEPCON, мы сравнили ее с архитектурами, используемыми в современных современных методах — Raptor-X (Wang et al., 2017), DNCON2 (Adhikari et al. , 2018), DeepCov (Jones and Kandathil, 2018) и PconsC4 (Michel et al. , 2018). Метод Raptor-X использует остаточные сети примерно с 60 сверточными слоями. Метод DNCON2 использует ансамблевую двухуровневую сверточную нейронную сеть, каждая из которых состоит из 7 слоев. Каждая сеть состоит из шести слоев с 16 фильтрами в каждом и дополнительного сверточного слоя с одним фильтром для генерации окончательных вероятностей контакта. Каждая сверточная сеть здесь имеет около 50 тысяч параметров.В методе DeepCov 441 входной канал сокращается до 64 с использованием слоя Maxout, а затем тестируются полностью сверточные слои различной глубины. DeepCov лучше всего работает при размере принимающего поля 15, то есть 7 сверточных слоев. Метод PconsC4 напрямую использует архитектуру U-Net, которая принимает входной объем 256 × 256 × 64, то есть входные каналы сначала будут проецироваться на 64 канала. Такая архитектура имеет 31 миллион параметров.
Используя ковариационную матрицу в качестве входной характеристики, когда мы используем набор данных DeepCov для обучения и проверки и белки PSICOV 150 в качестве тестового набора данных, мы обнаруживаем, что DEEPCON работает аналогично стандартной остаточной архитектуре (см.рис.4) на метике оценки P L / 5-LR . Однако на показателях P NC-LR и P NC-MLR производительность DEEPCON значительно выше, чем у стандартной сетевой архитектуры остаточного типа, полностью подключенной архитектуры CNN и архитектуры U-Net. Точно так же, используя функции последовательности в качестве входных данных, когда мы используем набор данных DNCON2 для обучения и домены белка CASP12 для тестирования, мы наблюдаем аналогичные результаты (см. Рис. 4). Высокая производительность архитектуры DEEPCON на этих двух очень разных наборах данных предполагает, что глубокие остаточные сети с выпадением являются надежными и хорошо работают для различных входных функций для прогнозирования контактов с белками.
Рис. 4.
Сравнение производительности различных архитектур ConvNet — полностью подключенных ConvNets (FCN), остаточных сетей с выпадением и расширением (DEEPCON), обычной остаточной сети и архитектуры, подобной U-Net — с использованием P L / 5- LR , P L-LR и P NC-MLR . Мы обучаем и проверяем, используя набор данных DeepCov, состоящий из 3456 белков, и тестируем (результаты здесь слева), используя набор данных PSICOV 150, используя функции ковариации (слева).Мы обучаем и проверяем, используя набор данных DNCON2, состоящий из 1426 белков, и тестируем, используя 62 белка в наборе данных CASP12 (результаты справа), используя функции последовательности (справа)
Рис. 4.
Сравнение производительности различных Архитектуры ConvNet — полностью подключенные ConvNets (FCN), остаточные сети с выпадением и расширением (DEEPCON), обычная остаточная сеть и архитектура, подобная U-Net — с использованием P L / 5-LR , P L-LR и P NC -MLR .Мы обучаем и проверяем, используя набор данных DeepCov, состоящий из 3456 белков, и тестируем (результаты здесь слева), используя набор данных PSICOV 150, используя функции ковариации (слева). Мы обучаем и проверяем, используя набор данных DNCON2, состоящий из 1426 белков, и тестируем, используя 62 белка в наборе данных CASP12 (результаты справа), используя функции последовательности (справа)
Набор данных DeepCov (3456 белков) PSICOV (150 белков) Матрица ковариации DeepCov (Jones and Kandathil, 2018) 85.8 55,1 DeepCov как (наша реализация) 88,6 58,2 DEEPCON 90,9 63,4 Набор данных DNCON2 (1426 белков) CASP12 (84 домена) Ковариационная матрица DEEPCON 55,9 36.3 Функции последовательности DNCON2 (Adhikari et al. , 2018) 59,9 39,1 DEEPCON 61,5 910 910 910 910 910 910 910 9100 набор данных
. Набор тестовых данных
. Используемые функции
. Архитектура
. P L / 5-LR . П L-LR . Набор данных DeepCov (3456 белков) PSICOV (150 белков) Матрица ковариации DeepCov (Джонс и Кандатил, 2018) 85,8 55.1 как наша реализация ) 88,6 58,2 DEEPCON 90,9 63,4 Функции последовательности DEEPCON 92.6 68,2 Набор данных DNCON2 (1426 белков) CASP12 (84 домена) Матрица ковариации DEEPCON 55,9 36,3 и другие. , 2018) 59,9 39,1 DEEPCON 61,5 41,0 Таблица 1.
Сравнение эффективности DEEPCON с DeepCov и данными
| Набор данных для обучения и проверки . | Набор тестовых данных . | Используемые функции . | Архитектура . | P L / 5-LR . | П L-LR . | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Набор данных DeepCov (3456 белков) | PSICOV (150 белков) | Матрица ковариации | DeepCov (Jones and Kandathil, 2018) | 85.8 | 55,1 | ||||||
| DeepCov как (наша реализация) | 88,6 | 58,2 | |||||||||
| DEEPCON | 90,9 | 63,4 | |||||||||
| Набор данных DNCON2 (1426 белков) | CASP12 (84 домена) | Ковариационная матрица | DEEPCON | 55,9 | 36.3 | ||||||
| Функции последовательности | DNCON2 (Adhikari et al. , 2018) | 59,9 | 39,1 | ||||||||
| DEEPCON | 61,5 | 41,0 901 с использованием функций последовательности, Мы сравнили эффективность DEEPCON с методом DNCON2 при обучении и тестировании на наборе данных 1426 белков, который использовался для обучения DNCON2. В то время как DNCON2 использует двухуровневый подход, используя информацию с пороговых значений расстояния, отличных от стандартных 8 Å, и использует ансамбль моделей, мы обучаем одну модель.Для обучения наших моделей мы используем тот же набор из 196 белков в качестве набора для проверки, а остальные — в качестве набора для обучения (как это было сделано в работе DNCON2) и оцениваем набор данных CASP12, состоящий из 84 доменов. Для всех наших прогнозов мы используем те же входные функции (сгенерированные для целей, а не доменов), которые использует DNCON2. На этих 84 доменах CASP12 мы обнаружили, что DEEPCON достигает на 3,2% выше P L / 2-LR и на 4,8% выше P L-LR (см. Таблицу 1). Для полноты изложения в таблице 1 мы также сообщаем о производительности нашей архитектуры DEEPCON, когда она обучена и проверена на наборе данных DeepCov с функциями последовательности в качестве входных данных и в наборе данных DNCON2 с функциями ковариации в качестве входных данных. Кроме того, чтобы убедиться, что улучшенные предсказания контактов действительно полезны, для 150 белков в наборе данных PSICOV мы спрогнозировали полные трехмерные (3D) модели с помощью CONFOLD2 (Adhikari and Cheng, 2018). CONFOLD2 здесь идеален, потому что он полностью полагается на входную прогнозируемую информацию о контактах для построения моделей, в отличие от методов, которые используют фрагменты шаблонов. Он итеративно выбирает верхние 0,1 л, 0,2 л, 0,3 л и т. Д. Входные контакты до 4,0 л, генерирует до 200 ловушек и автоматически выбирает пять лучших моделей.Для набора данных PSICOV, используя функции ковариации в качестве входных данных, мы предсказали контакты с помощью метода DeepCov и нашего метода DEEPCON и отфильтровали контакты, чтобы сохранить только контакты среднего и дальнего действия. Эти контакты были предоставлены в качестве входных данных для CONFOLD2 для получения трехмерных моделей полного атома. Затем мы оценили пять лучших моделей, предсказанных CONFOLD2, и сравнили лучшие из пяти. Сравнение прогнозируемых контактов с использованием P L-LR и лучших моделей с использованием TM-score (Zhang, 2005) показывает, что в среднем прогнозы контактов DEEPCON лучше, чем контакты DeepCov (см.рис.5). Из того же рисунка мы также делаем вывод, что улучшение DEEPCON не ограничивается белками, для которых обнаружено большое количество гомологичных последовательностей. Мы рассчитали эффективные гомологичные последовательности (Neff) с помощью программы «colstats» в пакете MetaPSICOV. Наконец, следуя практике оценки калибровки предсказанных контактов (Лю и др. , 2018; Джонс и Кандатил, 2018; Монастырский и др. , 2016) (то есть, чтобы проверить, занижены или переоценены наши вероятности), мы оценили точность контактов, предсказанных с различными доверительными интервалами, и обнаружили, что вероятности DEEPCON хорошо откалиброваны (см.рис.6). Рис. 5. Сравнение контактов, предсказанных методом DeepCov и нашим методом DEEPCON на наборе данных PSICOV150 с использованием P L-LR (слева) и лучших из пяти моделей, предсказанных CONFOLD2 (справа) с использованием TM-score. Средний балл TM-оценки лучших из пяти моделей по DEEPCON и DeepCov составляет 0,60 и 0,52 соответственно. Размер точек на графике соответствует относительной разнице в эффективном количестве последовательностей (Neff) во входном файле выравнивания, т.е.е. меньшие точки представляют белки с маленьким Neff. Значения Neff варьируются от 14 до 25 702 Рис. 5. Сравнение контактов, предсказанных методом DeepCov и нашим методом DEEPCON на наборе данных PSICOV150 с использованием P L-LR (слева) и лучшего из- ТОП-5 моделей, предсказанных CONFOLD2 (справа) с использованием TM-score. Средний балл TM-оценки лучших из пяти моделей по DEEPCON и DeepCov составляет 0,60 и 0,52 соответственно. Размер точек на графике соответствует относительной разнице в эффективном количестве последовательностей (Neff) во входном файле выравнивания, т.е.е. меньшие точки представляют белки с маленьким Neff. Диапазон значений Neff от 14 до 25 702 Рис. 6. Коробчатая диаграмма точности контактов DEEPCON при различных доверительных интервалах, спрогнозированная для набора данных PSICOV150 Рис. 6. Коробчатая диаграмма точности контактов DEEPCON при различных доверительных интервалах, прогнозируемая для набора данных PSICOV150 Мы считают, что есть три причины повышения производительности DEEPCON. В таблице 1 мы показываем, что когда архитектура DEEPCON масштабируется до архитектуры, аналогичной архитектуре метода DeepCov, улучшение по-прежнему остается значительным.Это говорит о том, что общие параметры обучения и тестирования (например, оптимизатор) и общая структура обучения, построенная с использованием Tensorflow и Keras, вносят свой вклад в улучшение. Более глубокая архитектура DEEPCON, состоящая из 32 остаточных блоков (фактически 64 сверточных слоя), и использование Dropout и BatchNormalization в остаточном блоке, как показано на рисунке 3, также вносят свой вклад в улучшение. 421″> 4 ВыводыМы обнаружили, что регуляризация с использованием исключения очень эффективна во всех архитектурах — полностью сверточных, остаточных или расширенных остаточных сетей.Мы также обнаружили, что расширенные сверточные методы дают незначительно лучшую производительность, чем обычные остаточные сети, но этот выигрыш усиливается, когда расширенные свертки комбинируются с отсевами. Мы считаем, что наши результаты в сочетании с такими методами, как использование нескольких пороговых значений расстояния (Adhikari et al. , 2018; Jones et al. , 2015; Michel et al. , 2018), ансамбль (Adhikari et al. , 2018; Wang et al. , 2017), прогнозирование фактических расстояний с использованием биннинга (Xu, 2018) и т. Д.Использование в других методах может значительно улучшить общую точность прогнозирования контакта. Мы также считаем, что наши выводы и архитектуры будут использоваться другими исследователями для продолжения разработки и повышения производительности с помощью более сложных и мощных архитектур, больших наборов данных для обучения и проверки, разработки дополнительных функций и выходных меток, а также посредством ансамбля моделей. 425″> ФинансированиеРабота частично поддержана грантом для открытия нового факультета Университета Миссури-Сент. Луи (UMSL) — бакалавриату, и премии UMSL Research Award 2018 — BA. Конфликт интересов : не объявлен. Ознакомьтесь со всеми предстоящими тестами навыков здесь. |